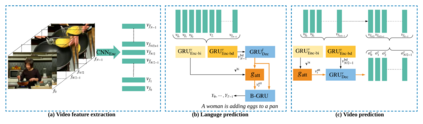
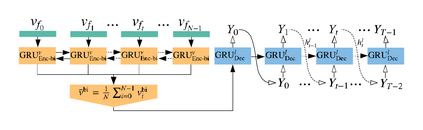
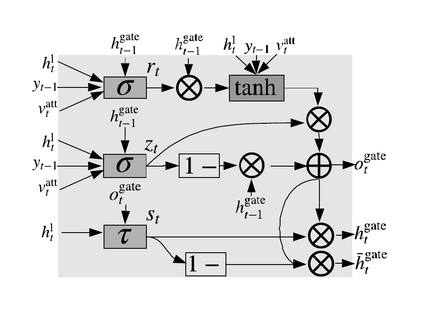
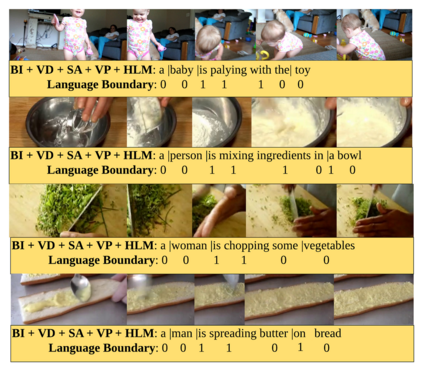
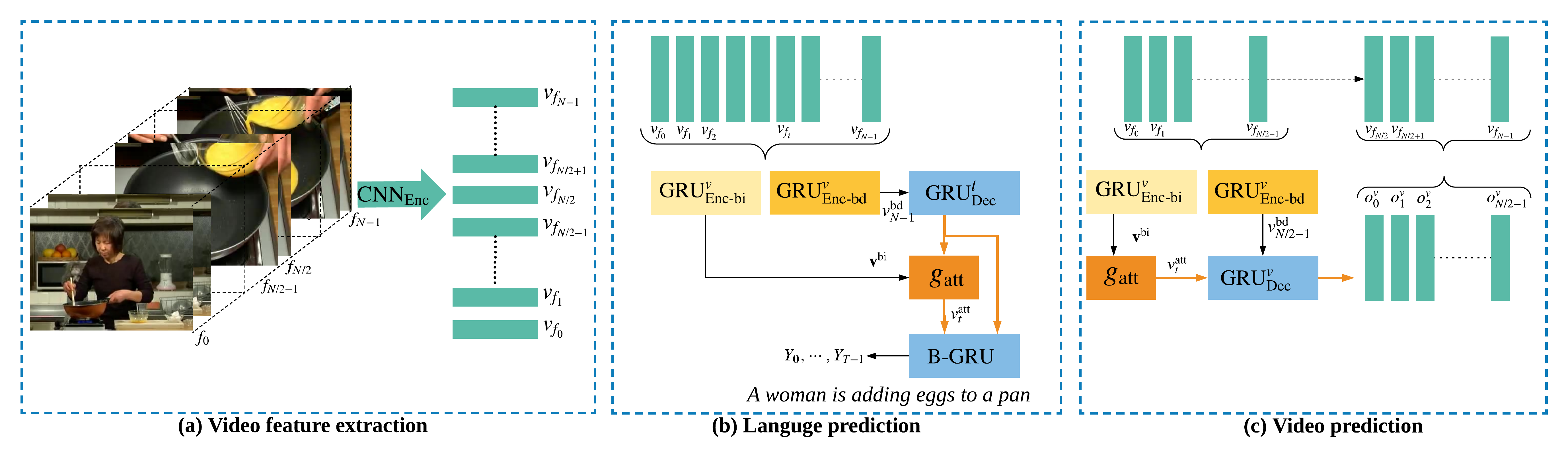
The explosion of video data on the internet requires effective and efficient technology to generate captions automatically for people who are not able to watch the videos. Despite the great progress of video captioning research, particularly on video feature encoding, the language decoder is still largely based on the prevailing RNN decoder such as LSTM, which tends to prefer the frequent word that aligns with the video. In this paper, we propose a boundary-aware hierarchical language decoder for video captioning, which consists of a high-level GRU based language decoder, working as a global (caption-level) language model, and a low-level GRU based language decoder, working as a local (phrase-level) language model. Most importantly, we introduce a binary gate into the low-level GRU language decoder to detect the language boundaries. Together with other advanced components including joint video prediction, shared soft attention, and boundary-aware video encoding, our integrated video captioning framework can discover hierarchical language information and distinguish the subject and the object in a sentence, which are usually confusing during the language generation. Extensive experiments on two widely-used video captioning datasets, MSR-Video-to-Text (MSR-VTT) \cite{xu2016msr} and YouTube-to-Text (MSVD) \cite{chen2011collecting} show that our method is highly competitive, compared with the state-of-the-art methods.
翻译:互联网上视频数据的爆炸要求有效和高效的技术,为无法观看视频的人自动生成字幕。尽管视频字幕研究取得了巨大进展,特别是在视频特征编码方面,但语言解码器在很大程度上仍然基于流行的 RNN 解码器,如LSTM, 倾向于使用与视频一致的常用词。在本文中,我们提议为视频字幕建立一个有边界意识的等级语言解码器,其中包括一个基于GRU的高级语言解码器,作为全球(高级)语言模型,以及一个基于低级别GRU的竞争性语言解码器,作为当地(口数级)语言编码器。最重要的是,我们为低级别GRU语言解码器引入了一个二进门,以探测语言边界界限。加上其他先进的部件,包括联合视频预测、共享软关注和边界识别视频编码,我们2011年的综合视频字幕框架可以发现等级语言信息,并区分主题和句中的标语,这通常在语言生成期间令人困惑。关于两种广泛使用的视频解析方法的大规模实验,即高频-甚高频MM-C 和高频 向高频-高频-高频-高频-高频-高频-高频-高频-高频-高频-高频-高频-高频-高频-高频-高频-高频-高频-高频-高射制数据解解解解解解解解制数据方法。