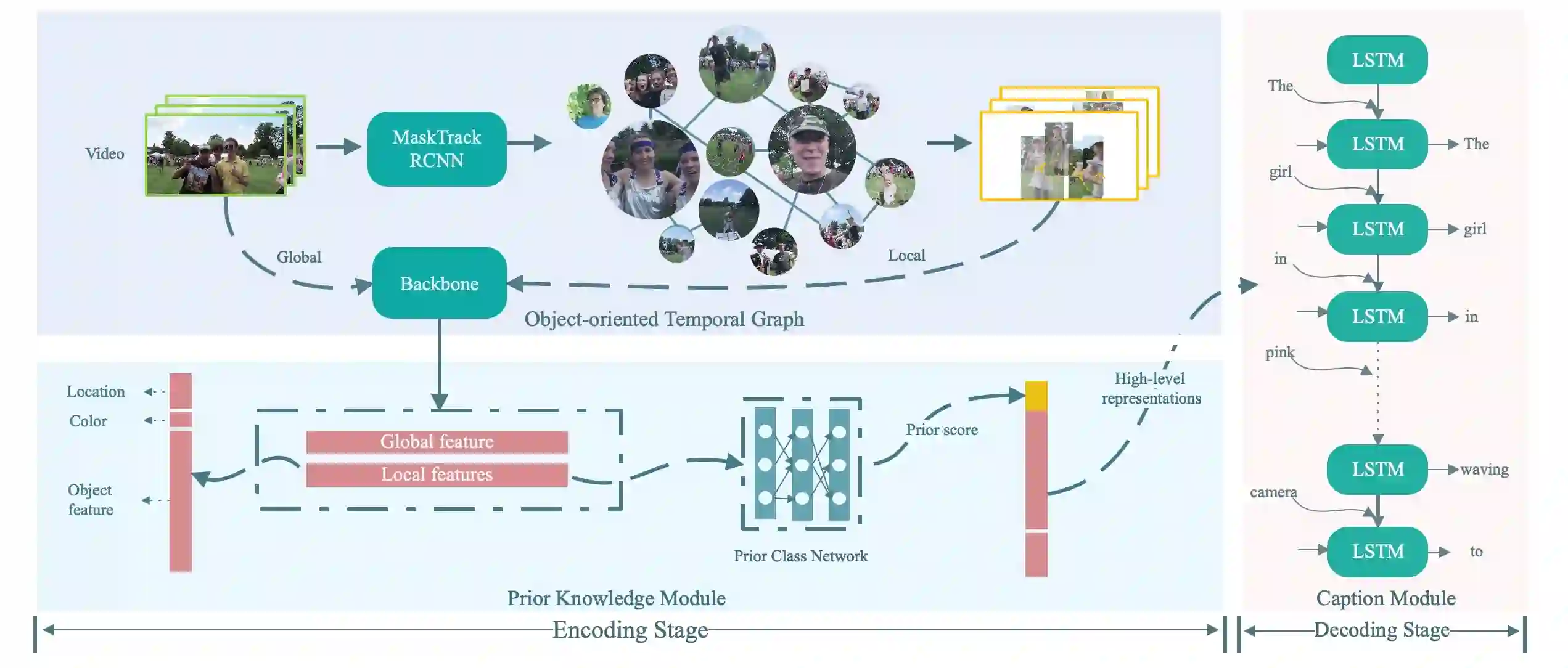
Traditional video captioning requests a holistic description of the video, yet the detailed descriptions of the specific objects may not be available. Besides, most methods adopt frame-level inter-object features and ambiguous descriptions during training, which is difficult for learning the vision-language relationships. Without associating the transition trajectories, these image-based methods cannot understand the activities with visual features. We propose a novel task, named object-oriented video captioning, which focuses on understanding the videos in object-level. We re-annotate the object-sentence pairs for more effective cross-modal learning. Thereafter, we design the video-based object-oriented video captioning (OVC)-Net to reliably analyze the activities along time with only visual features and capture the vision-language connections under small datasets stably. To demonstrate the effectiveness, we evaluate the method on the new dataset and compare it with the state-of-the-arts for video captioning. From the experimental results, the OVC-Net exhibits the ability of precisely describing the concurrent objects and their activities in details.
翻译:传统视频字幕要求对视频进行整体描述,但特定对象的详细描述可能无法提供。 此外,大多数方法在培训期间采用框架层面的跨对象特征和模糊描述,这对于学习视觉语言关系来说很难。这些基于图像的方法如果不将过渡轨迹联系起来,就无法理解带有视觉特征的活动。我们提议了一项新颖的任务,名为目标导向视频字幕,重点是了解目标层面的视频。我们重新注意到对象-感应配对,以便更有效地进行跨模式学习。随后,我们设计基于视频的面向对象的视频字幕(OVC)-Net,以可靠地分析活动,同时只使用视觉特征,在小型数据集下捕捉视觉语言链接。为了显示效果,我们评估新数据集的方法,并将其与视频字幕的状态进行比较。从实验结果来看,OVC-Net展示了准确描述同步对象及其活动的详细能力。