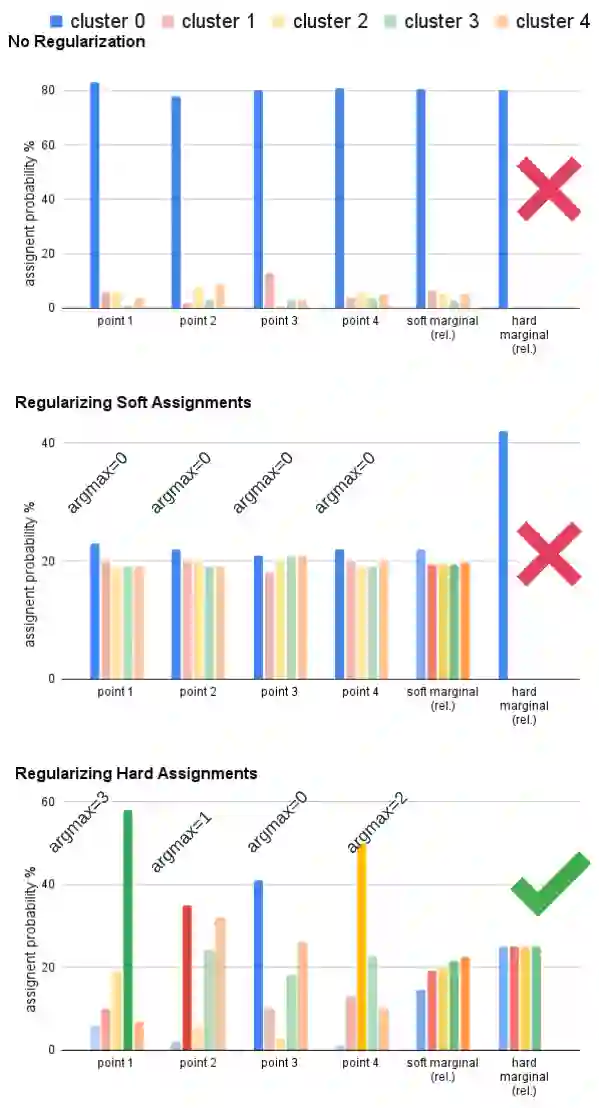
Online deep clustering refers to the joint use of a feature extraction network and a clustering model to assign cluster labels to each new data point or batch as it is processed. While faster and more versatile than offline methods, online clustering can easily reach the collapsed solution where the encoder maps all inputs to the same point and all are put into a single cluster. Successful existing models have employed various techniques to avoid this problem, most of which require data augmentation or which aim to make the average soft assignment across the dataset the same for each cluster. We propose a method that does not require data augmentation, and that, differently from existing methods, regularizes the hard assignments. Using a Bayesian framework, we derive an intuitive optimization objective that can be straightforwardly included in the training of the encoder network. Tested on four image datasets and one human-activity recognition dataset, it consistently avoids collapse more robustly than other methods and leads to more accurate clustering. We also conduct further experiments and analyses justifying our choice to regularize the hard cluster assignments. Code is available at https://github.com/Lou1sM/online_hard_clustering.
翻译:暂无翻译