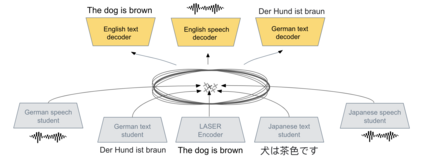
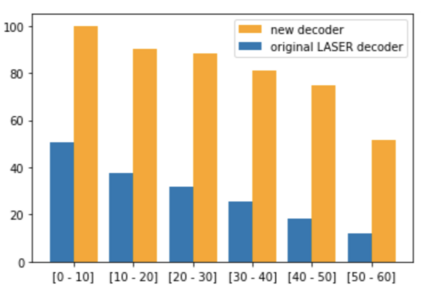
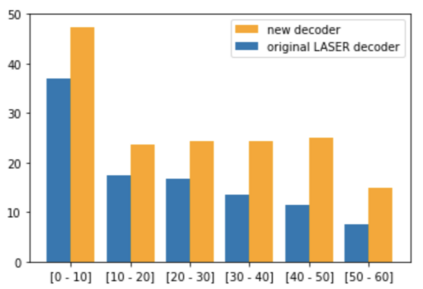
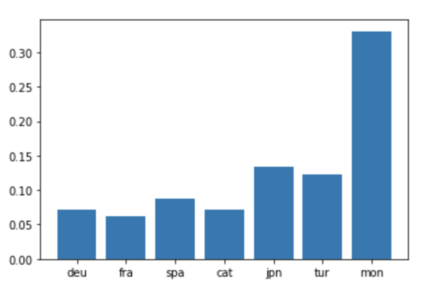
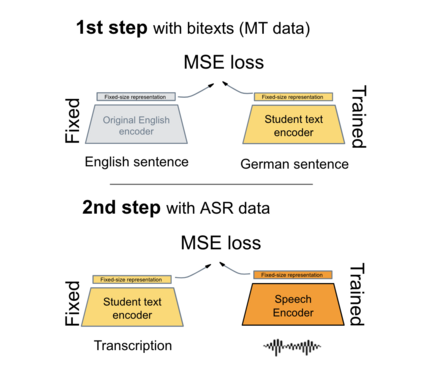
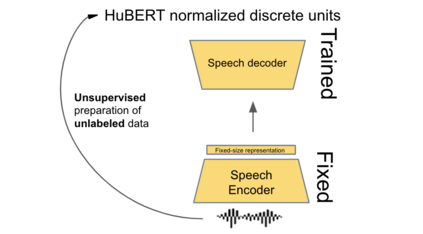
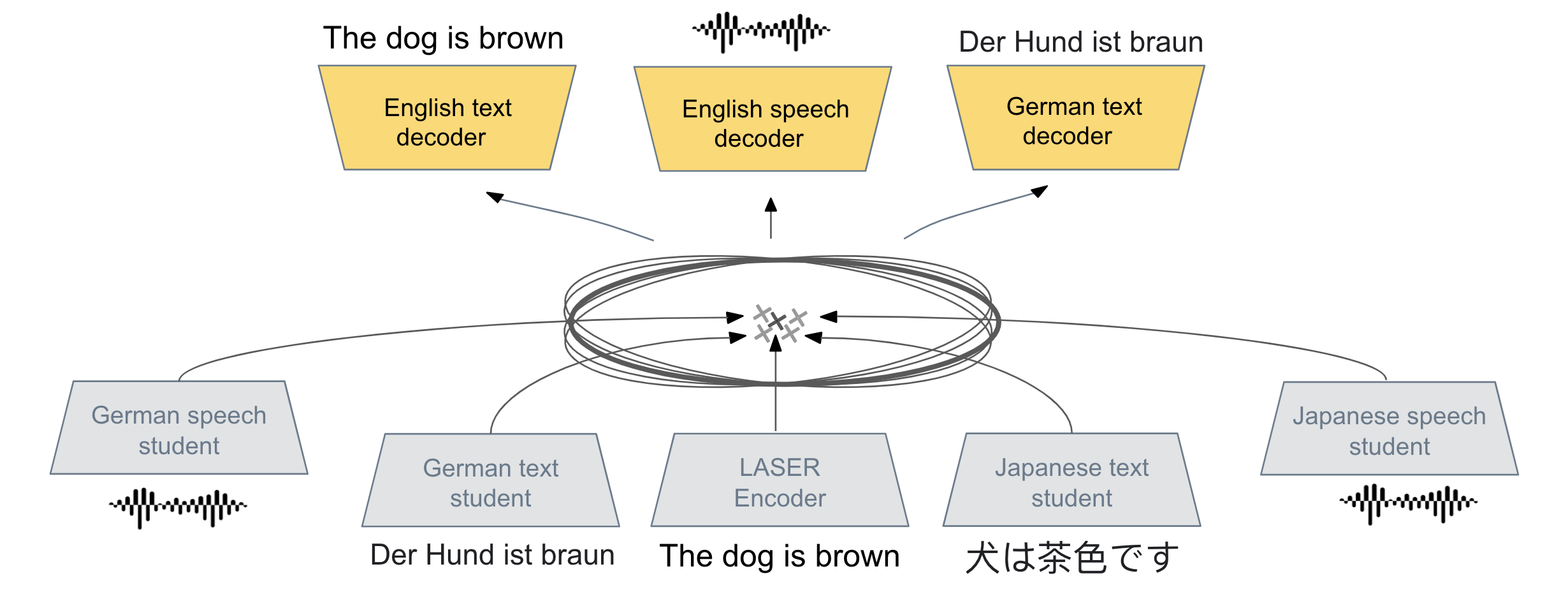
We present a new approach to perform zero-shot cross-modal transfer between speech and text for translation tasks. Multilingual speech and text are encoded in a joint fixed-size representation space. Then, we compare different approaches to decode these multimodal and multilingual fixed-size representations, enabling zero-shot translation between languages and modalities. All our models are trained without the need of cross-modal labeled translation data. Despite a fixed-size representation, we achieve very competitive results on several text and speech translation tasks. In particular, we significantly improve the state-of-the-art for zero-shot speech translation on Must-C. Incorporating a speech decoder in our framework, we introduce the first results for zero-shot direct speech-to-speech and text-to-speech translation.
翻译:我们提出了一个在语言和翻译任务文本之间进行零点点滴跨式交叉传输的新办法。多语种语言和文本被编码成一个共同的固定规模代表空间。然后,我们比较了解码这些多语种和多语种固定规模代表的不同办法,使得语言和模式之间能够进行零点滴翻译。我们的所有模型都经过培训,不需要跨模式标签翻译数据。尽管有固定规模的代表,但我们在一些文本和语言翻译任务上取得了非常有竞争力的成果。特别是,我们大大改进了在Must-C上零点滴语音翻译的最新技术。在我们的框架中加入一个语音解码器,我们介绍了零点滴直接语音对语音和文本对语音翻译的第一个结果。