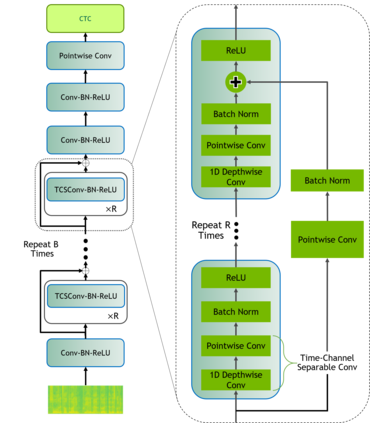
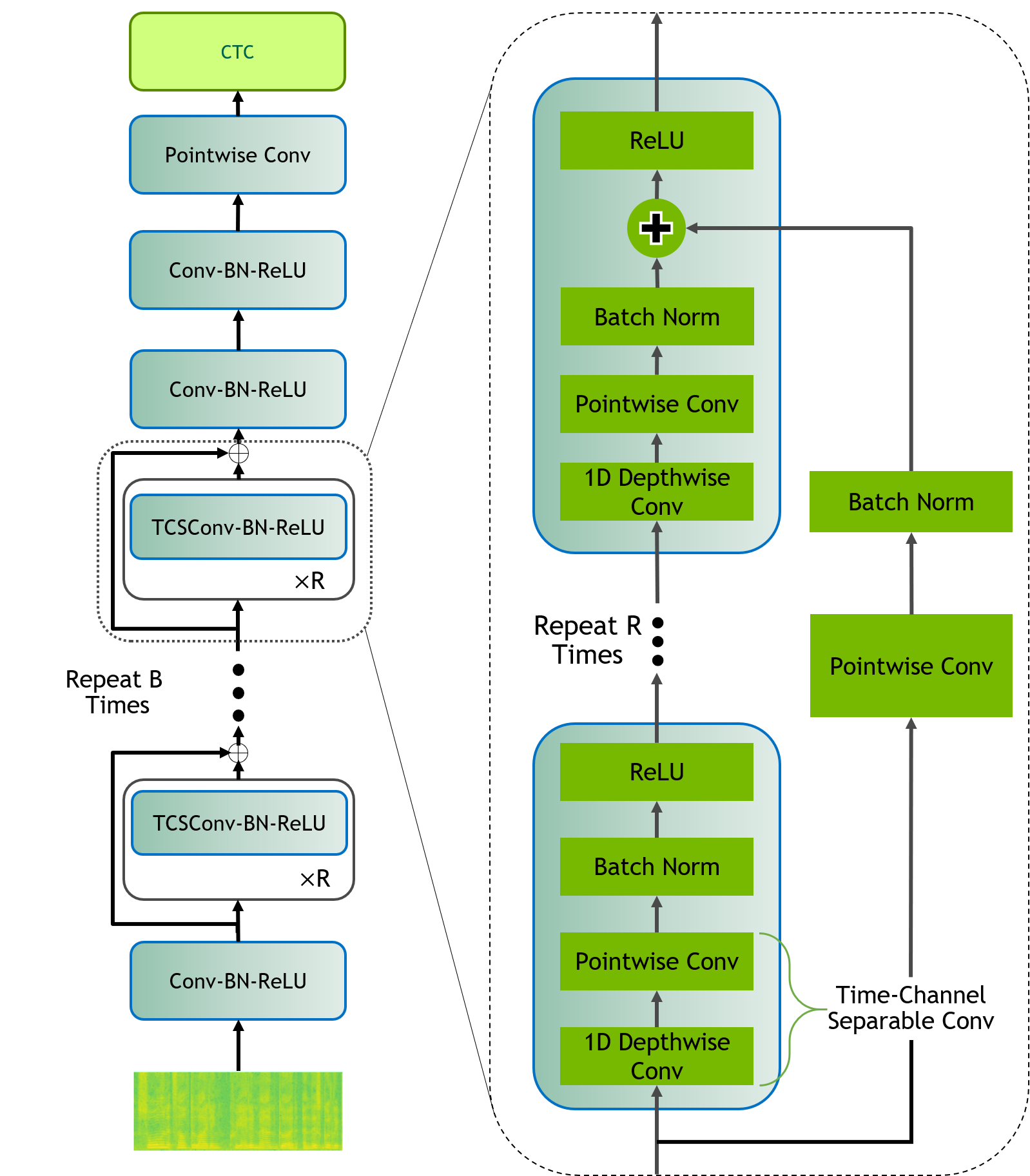
End-to-end neural automatic speech recognition systems achieved recently state-of-the-art results, but they require large datasets and extensive computing resources. Transfer learning has been proposed to overcome these difficulties even across languages, e.g., German ASR trained from an English model. We experiment with much less related languages, reusing an English model for Czech ASR. To simplify the transfer, we propose to use an intermediate alphabet, Czech without accents, and document that it is a highly effective strategy. The technique is also useful on Czech data alone, in the style of coarse-to-fine training. We achieve substantial eductions in training time as well as word error rate (WER).
翻译:端到端的神经自动语音识别系统最近取得了最新的最新成果,但它们需要大量的数据集和大量的计算资源。建议转移学习,以克服这些困难,即使是在各种语言之间,例如,从英语模型中培训的德国ASR。我们试验了少得多的相关语言,在捷克ASR中重新使用英语模型。为了简化传输,我们建议使用中间字母,捷克语没有口音,并记录这是一个非常有效的战略。这种技术还仅对捷克数据有用,以粗略到软体培训的方式。我们在培训时间和字词错误率方面实现了大量引入(WER ) 。