【论文推荐】最新六篇命名实体识别相关论文—跨专业医学、阿拉伯命名实体、中国临床、深度多任务学习、多模态、图卷积网络
【导读】专知内容组整理了最近六篇命名实体识别(Named Entity Recognition)相关文章,为大家进行介绍,欢迎查看!
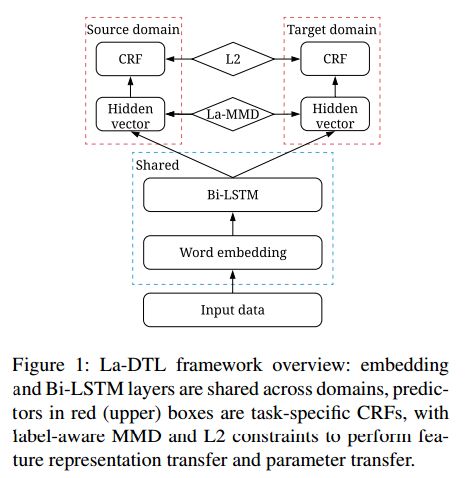
1.Label-aware Double Transfer Learning for Cross-Specialty Medical Named Entity Recognition(基于标签感知双迁移学习的跨专业医学命名实体识别)
作者:Zhenghui Wang,Yanru Qu,Liheng Chen,Jian Shen,Weinan Zhang,Shaodian Zhang,Yimei Gao,Gen Gu,Ken Chen,Yong Yu
NAACL HLT 2018
机构:Shanghai Jiao Tong University
摘要:We study the problem of named entity recognition (NER) from electronic medical records, which is one of the most fundamental and critical problems for medical text mining. Medical records which are written by clinicians from different specialties usually contain quite different terminologies and writing styles. The difference of specialties and the cost of human annotation makes it particularly difficult to train a universal medical NER system. In this paper, we propose a label-aware double transfer learning framework (La-DTL) for cross-specialty NER, so that a medical NER system designed for one specialty could be conveniently applied to another one with minimal annotation efforts. The transferability is guaranteed by two components: (i) we propose label-aware MMD for feature representation transfer, and (ii) we perform parameter transfer with a theoretical upper bound which is also label aware. We conduct extensive experiments on 12 cross-specialty NER tasks. The experimental results demonstrate that La-DTL provides consistent accuracy improvement over strong baselines. Besides, the promising experimental results on non-medical NER scenarios indicate that La-DTL is potential to be seamlessly adapted to a wide range of NER tasks.
期刊:arXiv, 2018年4月28日
网址:
http://www.zhuanzhi.ai/document/bcba3d4c63e7c2ed0538f1ce8d451d56
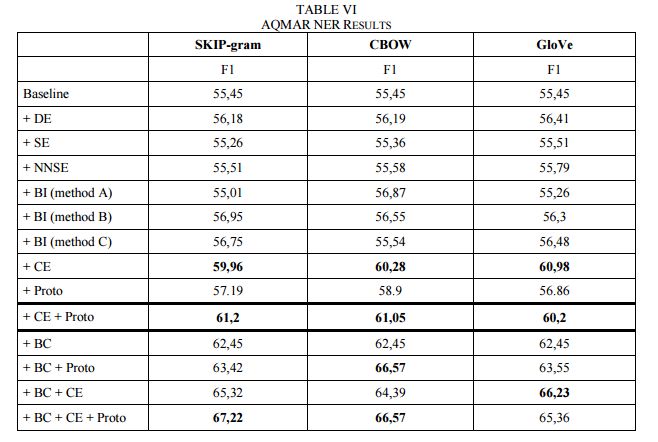
2.Arabic Named Entity Recognition using Word Representations(基于词表示的阿拉伯命名实体识别)
作者:Ismail El Bazi,Nabil Laachfoubi
摘要:Recent work has shown the effectiveness of the word representations features in significantly improving supervised NER for the English language. In this study we investigate whether word representations can also boost supervised NER in Arabic. We use word representations as additional features in a Conditional Random Field (CRF) model and we systematically compare three popular neural word embedding algorithms (SKIP-gram, CBOW and GloVe) and six different approaches for integrating word representations into NER system. Experimental results show that Brown Clustering achieves the best performance among the six approaches. Concerning the word embedding features, the clustering embedding features outperform other embedding features and the distributional prototypes produce the second best result. Moreover, the combination of Brown clusters and word embedding features provides additional improvement of nearly 10% in F1-score over the baseline.
期刊:arXiv, 2018年4月16日
网址:
http://www.zhuanzhi.ai/document/9769b21eaaf1eda7ce077bdaeb7a33f4
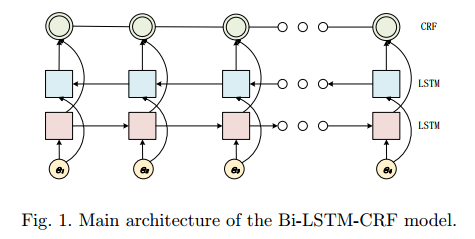
3.Incorporating Dictionaries into Deep Neural Networks for the Chinese Clinical Named Entity Recognition(在深度神经网络中引入字典进行中国临床命名实体识别)
作者:Qi Wang,Yuhang Xia,Yangming Zhou,Tong Ruan,Daqi Gao,Ping He
机构:East China University of Science and Technology
摘要:Clinical Named Entity Recognition (CNER) aims to identify and classify clinical terms such as diseases, symptoms, treatments, exams, and body parts in electronic health records, which is a fundamental and crucial task for clinical and translational research. In recent years, deep neural networks have achieved significant success in named entity recognition and many other Natural Language Processing (NLP) tasks. Most of these algorithms are trained end to end, and can automatically learn features from large scale labeled datasets. However, these data-driven methods typically lack the capability of processing rare or unseen entities. Previous statistical methods and feature engineering practice have demonstrated that human knowledge can provide valuable information for handling rare and unseen cases. In this paper, we address the problem by incorporating dictionaries into deep neural networks for the Chinese CNER task. Two different architectures that extend the Bi-directional Long Short-Term Memory (Bi-LSTM) neural network and five different feature representation schemes are proposed to handle the task. Computational results on the CCKS-2017 Task 2 benchmark dataset show that the proposed method achieves the highly competitive performance compared with the state-of-the-art deep learning methods.
期刊:arXiv, 2018年4月14日
网址:
http://www.zhuanzhi.ai/document/6681379ba4b4a5e0b4476ac6b8ca35ac
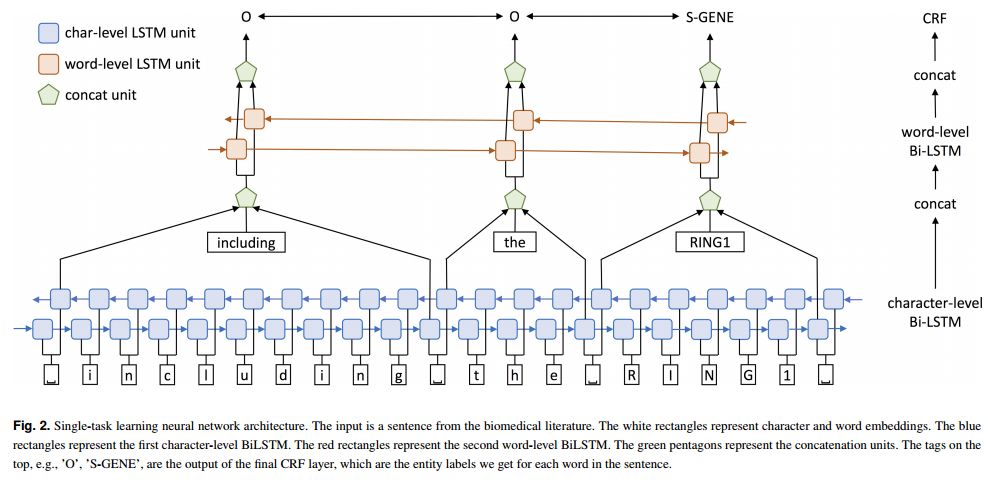
4.Cross-type Biomedical Named Entity Recognition with Deep Multi-Task Learning(基于深度多任务学习的跨类型生物医学命名实体识别)
作者:Xuan Wang,Yu Zhang,Xiang Ren,Yuhao Zhang,Marinka Zitnik,Jingbo Shang,Curtis Langlotz,Jiawei Han
机构:University of Illinois at Urbana-Champaign,University of Southern California,Stanford University
摘要:Motivation: Biomedical named entity recognition (BioNER) is the most fundamental task in biomedical text mining. State-of-the-art BioNER systems often require handcrafted features specifically designed for each type of biomedical entities. This feature generation process requires intensive labors from biomedical and linguistic experts, and makes it difficult to adapt these systems to new biomedical entity types. Although recent studies explored using neural network models for BioNER to free experts from manual feature generation, these models still require substantial human efforts to annotate massive training data. Results: We propose a multi-task learning framework for BioNER that is based on neural network models to save human efforts. We build a global model by collectively training multiple models that share parameters, each model capturing the characteristics of a different biomedical entity type. In experiments on five BioNER benchmark datasets covering four major biomedical entity types, our model outperforms state-of-the-art systems and other neural network models by a large margin, even when only limited training data are available. Further analysis shows that the large performance gains come from sharing character- and word-level information between different biomedical entities. The approach creates new opportunities for text-mining approaches to help biomedical scientists better exploit knowledge in biomedical literature.
期刊:arXiv, 2018年4月5日
网址:
http://www.zhuanzhi.ai/document/314a80c4a2a17112d73f40d340dac1fd
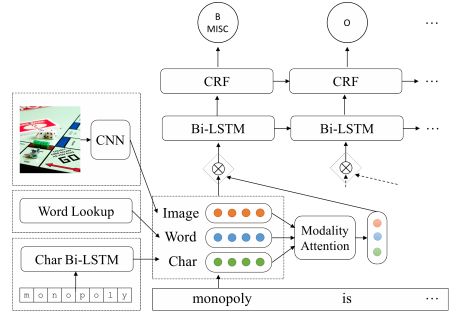
5.Multimodal Named Entity Recognition for Short Social Media Posts(面向短社交媒体帖子的多模态命名实体识别)
作者:Seungwhan Moon,Leonardo Neves,Vitor Carvalho
机构:Carnegie Mellon University
摘要:We introduce a new task called Multimodal Named Entity Recognition (MNER) for noisy user-generated data such as tweets or Snapchat captions, which comprise short text with accompanying images. These social media posts often come in inconsistent or incomplete syntax and lexical notations with very limited surrounding textual contexts, bringing significant challenges for NER. To this end, we create a new dataset for MNER called SnapCaptions (Snapchat image-caption pairs submitted to public and crowd-sourced stories with fully annotated named entities). We then build upon the state-of-the-art Bi-LSTM word/character based NER models with 1) a deep image network which incorporates relevant visual context to augment textual information, and 2) a generic modality-attention module which learns to attenuate irrelevant modalities while amplifying the most informative ones to extract contexts from, adaptive to each sample and token. The proposed MNER model with modality attention significantly outperforms the state-of-the-art text-only NER models by successfully leveraging provided visual contexts, opening up potential applications of MNER on myriads of social media platforms.
期刊:arXiv, 2018年2月22日
网址:
http://www.zhuanzhi.ai/document/667e8fca653da891656324569315a084
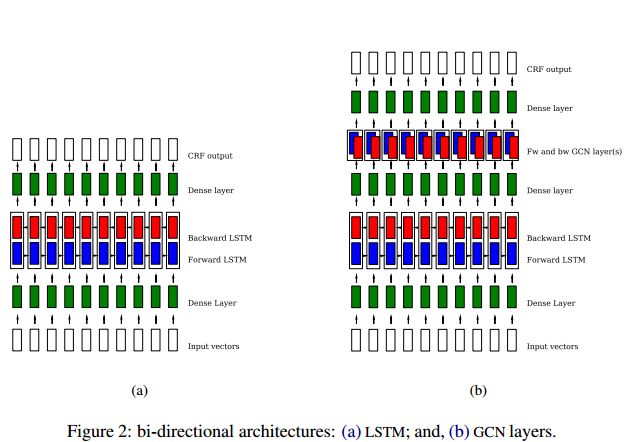
6.Graph Convolutional Networks for Named Entity Recognition(基于图卷积网络的命名实体识别)
作者:A. Cetoli,S. Bragaglia,A. D. O'Harney,M. Sloan
摘要:In this paper we investigate the role of the dependency tree in a named entity recognizer upon using a set of GCN. We perform a comparison among different NER architectures and show that the grammar of a sentence positively influences the results. Experiments on the ontonotes dataset demonstrate consistent performance improvements, without requiring heavy feature engineering nor additional language-specific knowledge.
期刊:arXiv, 2018年2月14日
网址:
http://www.zhuanzhi.ai/document/93b2ed30e47f9676a26dc34372095abc
-END-
专 · 知
人工智能领域主题知识资料查看与加入专知人工智能服务群:
【专知AI服务计划】专知AI知识技术服务会员群加入与人工智能领域26个主题知识资料全集获取

[点击上面图片加入会员]
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请加专知小助手微信(扫一扫如下二维码添加),加入专知主题群(请备注主题类型:AI、NLP、CV、 KG等)交流~

请关注专知公众号,获取人工智能的专业知识!
点击“阅读原文”,使用专知


