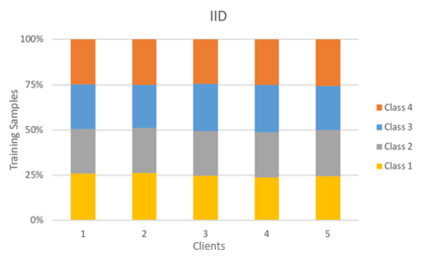
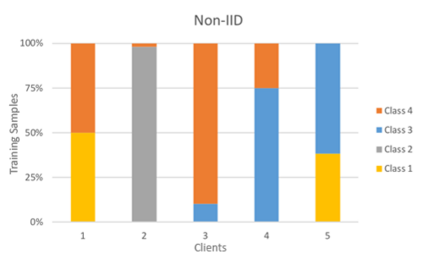
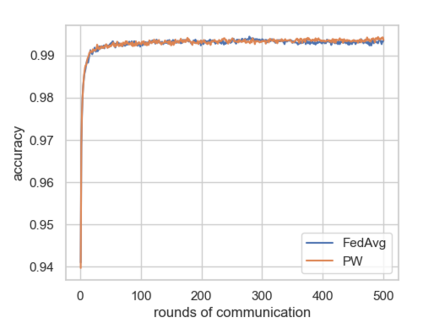
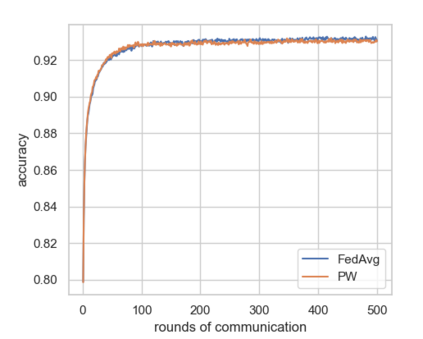
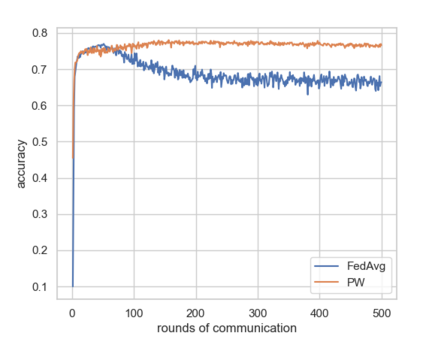
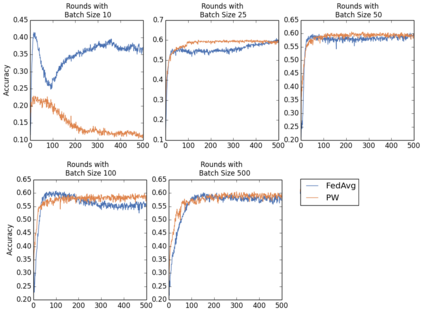
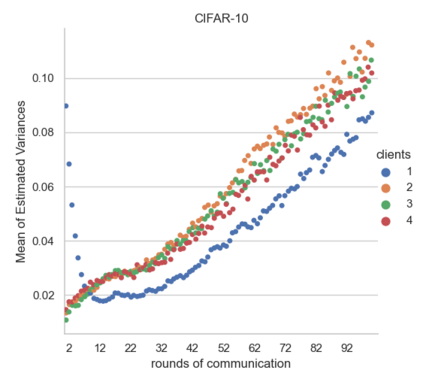
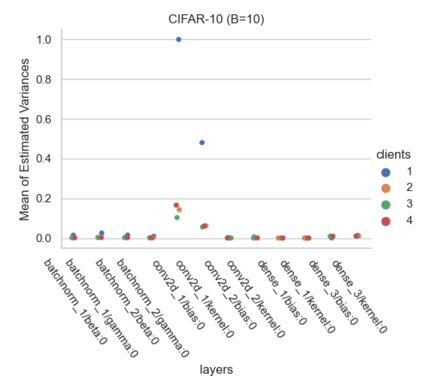
Federated Learning using the Federated Averaging algorithm has shown great advantages for large-scale applications that rely on collaborative learning, especially when the training data is either unbalanced or inaccessible due to privacy constraints. We hypothesize that Federated Averaging underestimates the full extent of heterogeneity of data when the aggregation is performed. We propose Precision-weighted Federated Learning a novel algorithm that takes into account the variance of the stochastic gradients when computing the weighted average of the parameters of models trained in a Federated Learning setting. With Precision-weighted Federated Learning, we provide an alternate averaging scheme that leverages the heterogeneity of the data when it has a large diversity of features in its composition. Our method was evaluated using standard image classification datasets with two different data partitioning strategies (IID/non-IID) to measure the performance and speed of our method in resource-constrained environments, such as mobile and IoT devices. We obtained a good balance between computational efficiency and convergence rates with Precision-weighted Federated Learning. Our performance evaluations show 9% better predictions with MNIST, 18% with Fashion-MNIST, and 5% with CIFAR-10 in the non-IID setting. Further reliability evaluations ratify the stability in our method by reaching a 99% reliability index with IID partitions and 96% with non-IID partitions. In addition, we obtained a 20x speedup on Fashion-MNIST with only 10 clients and up to 37x with 100 clients participating in the aggregation concurrently per communication round. The results indicate that Precision-weighted Federated Learning is an effective and faster alternative approach for aggregating private data, especially in domains where data is highly heterogeneous.
翻译:使用联邦阅读联合会的联邦学习联合会算法显示,在依靠协作学习的大规模应用中,特别是当培训数据由于隐私限制而不平衡或无法获取时,使用联邦学习联合会使用联邦阅读联合会的数据显示出巨大的优势。我们假设,在进行汇总时,联邦阅读联合会低估了数据的所有异质性。我们提议采用精密加权联邦学习联合会的新算法,在计算在联邦学习联合会设置中所培训模型参数的加权平均数时,考虑到随机梯度的差异。随着精密加权联邦学习,我们提供了一种替代平均方法,在数据构成具有巨大多样性时,利用数据异质性。我们用两种不同的数据分隔战略(IID/非IID)评估了标准图像分类数据集,以衡量我们在资源紧张的环境中,如移动和IOT设备,我们计算效率和趋同精度精度联邦学习的混合率之间,我们提供了一种良好的平衡。我们的业绩评估显示,在数据构成其构成高度多样化特点时,我们的数据不具有9 %的国际数据分类,在IMISIMII中,以更精确的IMISIMII数据进行更精确的频率评估,在10的IMIS前,在进行更精确的IMFISISI中,在进行更精确评估时,在10-IMISISISISISB中,在进行更精确评估时,在使用一种更精确的方法是建立更精确的方法,在10-ISISISISISI。