Federated Learning: 架构

工作原因,听到和使用Federated Learning框架很多,但是对框架内的算法和架构了解不够细致,特读论文以记之。
这个系列计划要写的文章包括:
-
Federated Learning: 问题与优化算法 -
Federated Learning: 架构(本篇)
Overall
正如上篇所言,Federated Learning,中文名联合学习,是用于保护用户隐私的一个机器学习框架。
正常来说,现在的机器学习模型都是把数据带到代码面前来,即数据被收集到服务器端,然后进行训练。联合学习则是把代码发送到数据端,从而能够使得用户的数据无需上传到服务器端就可以参与模型的训练。
既然数据不上传,那么client端需要上传什么呢?答案是上传模型的梯度,服务器端负责把梯度进行聚合得到最终的模型。同时,在client端开始训练之前,也会去服务器端去拉取最新的模型参数。
在优化这块,联合学习采用的是大batch同步梯度训练,这个方式也是最近的趋势,即便数据都在服务器端,现在也倾向采用这样的方式进行训练。我们后面也会有文章对此进行介绍。
论文解决了很多实用性的问题,比如:
-
设备可达性和局部数据分布的相关性 -
不可靠的设备连接 -
被中断的任务执行 -
跨设备的同步任务,不同的设备可达性不同 -
设备上有限的存储和计算资源
框架协议
了解系统架构之前,首先来了解一下框架上的协议。
联合学习的参与者有两个,FL Server和device,每一个联合学习任务(FL task)都会在一组设备上进行学习,这一组设备被称作FL polulation。
和普通的神经网络学习一样,联合学习的每个模型也是多次梯度下降得到的。但FL每次梯度下降的过程是:
-
Selection: 从所有可达设备中选取一部分,一般是几百个。 -
Configuration: 将FL plan和FL checkpoint发给这些设备。 -
Reporting: 服务器端等待device报告梯度更新。
这三个步骤放在一起,我们称之为一轮训练,也就是一个round。如下图所示。

如上图所示,那些超时没有返回的设备会被忽略掉,称之为drop,当被drop的设备超过一定比例时,这个round被会放弃。因而这个round被成功完成需要三个参数:
-
goal count: 目标数目,即参与这轮的设备需要有多少 -
timeout: 超时时间是多少 -
minimum percentage of goal count: 即容忍率,容忍多少设备被drop。
框架协议之Pace Steering
框架会管理与设备的连接,称之为Pace Steering, 中文或可翻译为步调控制。为了使得系统更具有可扩展性,需要这个管理策略即能处理小的FL population,又能处理大的FL population。
步调控制基于一种非常简单的策略,即告诉device何时再次重新连接。对于小的FL population,步调控制需要保证在某一时刻有足够的设备保持连接,同时告诉不需要的设备下次连接的时间,从而尽可能的保证下次连接设备比较集中。而对于大的FL population,步调控制会尽量随机化设备的连接时间来做负载均衡。
设备
Device的第一个责任就是存储本地数据,为了使得这些数据可用,需要实现FL框架提供的API,这样数据在逻辑上可以表达为FL Runtime。数据存储的方式可以多样,例如可以把数据存储到SQLite中,也可以是其他的数据库。
FL框架推荐限制存储的数据量,并对过时的数据进行清理。同时数据在存储的时候要予以加密。数据可以在具体的某个app内,也可以在app之间共享。
每个app可以通过通过提供FL population name和注册example store来建立FL runtime。此时,Android系统会使用JobScheduler来运行FL runtime。为了使得FL runtime不对用户产生影响,这个FL runtime job会在手机充电且连接wifi且IDLE状态的时候才会启动。
Device上的结构如下图所示:
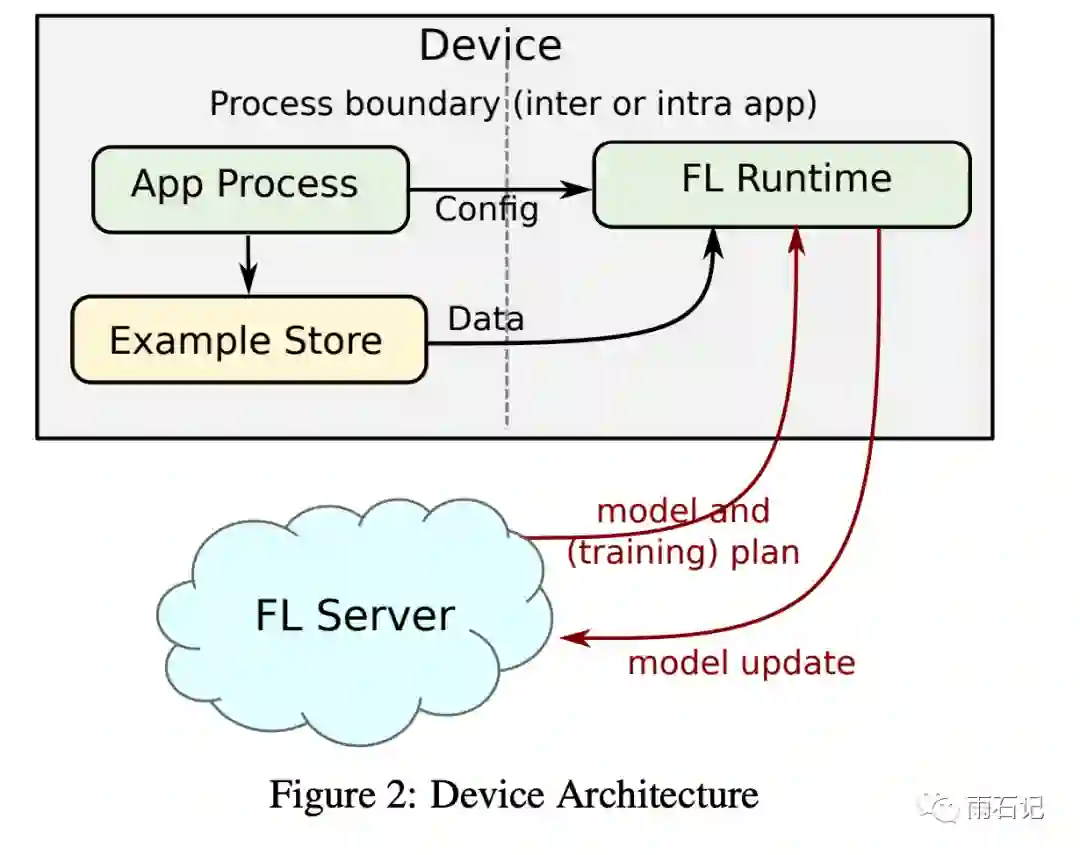
FL runtime有以下几种职责:
-
Job Invocation: 和FL Server联系并告知server设备已经准备好可以参与任务了。 -
Task Execution: 如果设备被选中,那么就从example store中拉取数据,并进行模型的训练。 -
Reporting: 训练结束之后,向server端传送梯度和指标,然后清空临时占用的资源。
设备的占用是Multi-Tenancy的,即设备可以参与多个联合学习任务。
设备是匿名参与训练的,即没有任何用户信息需要提供,但是为了防止虚假设备对FL框架进行攻击,使用Android的remote attestation mechanism来确保参与的device都是真机。
服务器端
服务器端需要应对的情况变化很大:
-
population size可能从几十到几百万 -
更新的梯度可能从几十k到几十兆 -
流量的区域性变化很大,(因为时区的关系,设备一般在晚上才会变为IDLE,充电,连接wifi的状态)
为了应对这些需求,服务器端的开发主要采用了参与者模式,每个参与者都会处理序列式的消息或者事件。例如,收到某消息后,参与者可以做一些本地操作,或者发送消息给其他的参与者,又或者动态的创建参与者。
用了参与者模式后,就可以动态的管理资源,比如可以在某个地理区域的服务器上创建更多的临时实例。
不同的参与者角色如下图:
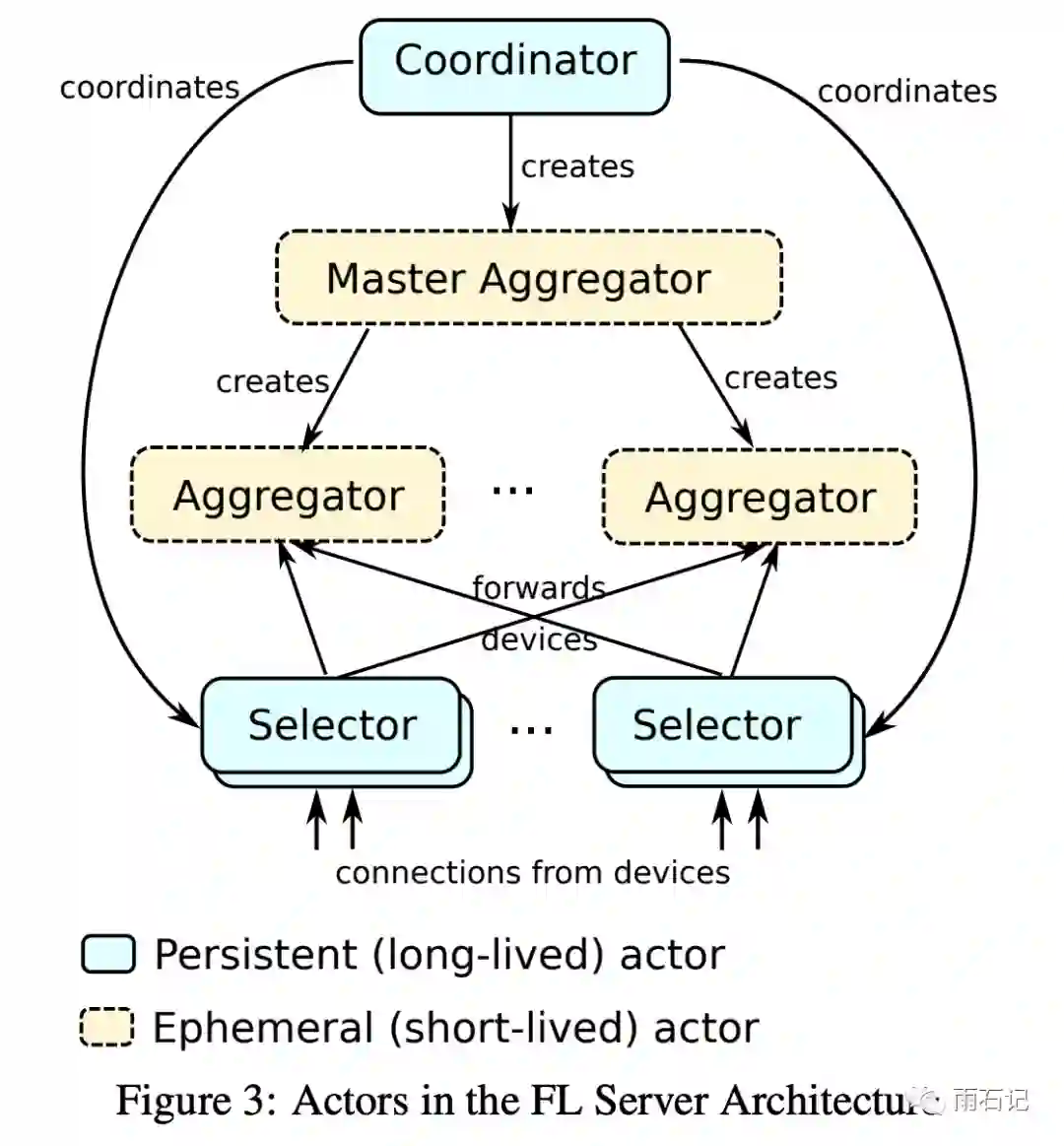
-
Coordeinator: 协调者,最顶层的参与者,确保全局的同步训练,每个协调者负责一个FL population。协调者会将自己的地址和FL popluation注册到一个共享锁服务里。所以,一个FL population只有一个协调者。协调者主要和选择者通信,从选择者那里接受有多少连接设备的信息,然后告诉选择者需要选多少设备来参与训练。同时,协调者还会创建Master Aggregator来管理每一轮的训练。 -
Selector: 选择者,负责和设备联系,同时从协调者那里获取需要多少设备的信息,还需要做决断来确定那些设备可以被接受,那些需要拒绝等下一次连接。在Aggregator创建后,向它们移交可以被接受的设备。Selector可以被分布式的分散在设备近的地方,从而降低总体的通信量。 -
Master Aggregators: 主聚合器,负责管理一个round,创建聚合器,收集聚合训练结果。
信息在聚合到主聚合器之前是不会被持久化存储的,这样避免了分布式持久化的问题,同时,内存聚合也避免了针对持久化数据的攻击。
Selection, Configuration和Reporting这三个步骤中,Selection并不依赖于上一个round的信息,因而,可以使用流水线式的并行来进行优化。
每个参与者都有可能失败,如果Aggregator或者Selector失败,只有跟它们连接的设备会丢失,并不一定会影响整个round。如果Master Aggregator失败,那么这个round就失败了,但是Coordinator会重新创建Master Aggregator。而如果Coordinator失败了,Selector会负责重建它,因为Coordinator在一个共享锁服务里,所以Coordinator只会被重建一次。
分析
有太多的因素会影响到这个框架了,虽然正确的实行FL任务不会影响用户使用,但发生问题的话就说不准了。因而,能够采集必要的信息或者失败的类型对整个系统的优化至关重要。
Device端需要运行计算密集型的操作,因而必须避免手机电池或者带宽等的损耗。为了保证这一点,很多和device健康相关的信息记录下来,比如:
-
训练开始时的device状态 -
多久运行一次训练 -
运行一次训练需要多长时间 -
占用了多少内存 -
遇到了哪些错误 -
系统版本、FL runtime版本 -
设备完成到了哪个stage
这些log不会包含任何用户相关信息(Personally Identifiable Information, PII),且会被聚合到一起展示成dashboard。
类似的,在Server端也需要采集信息,比如多少设备被某个round采用/拒绝。
Secure Aggregation
Secure Aggregation是在一个round内四轮交互的协议。这个协议需要在加密的同时保证能容忍一定的丢失率。
-
Prepare: 前两轮是准备阶段,设备建立shared secrets。 -
Commit: 设备将加密的梯度更新传到服务器端。 -
Finalizaiton: 设备传递足够的加密信息过来,从而服务器端可以解密,此时已经断掉的device不会传过来,从而丢掉的device的梯度就不会被aggregate了。
工具和工作流
开发者在开发FL的任务时,跟普通的data-center的模型不同:
-
数据无法直接接触到,所以需要使用模拟数据来测试。 -
模型不能交互式的运行,必须编译成FL plan去部署 -
因为FL plan需要在设备上运行,所以正确性和兼容性需要在框架上验证。
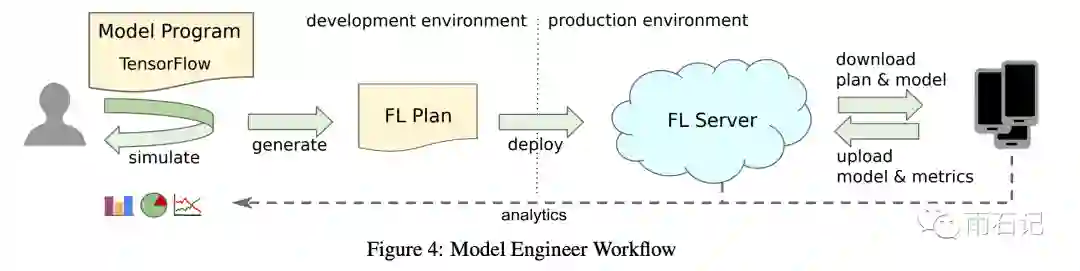
建模需要开发者自行完成,代码和普通的TF代码类似,只不过需要实现某些FL的接口;超参数的调优也一般在代理数据上完成。在FL的开发中,开发者只需要完成这一点。
FL plan是开发完成之后部署前由框架生成的,其中包含分为device端和server端,
-
Device端: -
Tensorflow Graph -
数据选取条件 -
如何batch数据 -
device上run多少epoch等 -
Server端: -
聚合逻辑
因为Tensorflow的不同版本会有区别,所以FL infra还需要支持FL plan的version化。即生成和部署的tensorflow版本一致版本的FL plan。
执行情况
每个round只有一小部分device参与训练,而因为device在充电,连接wifi,IDLE的情况下才能进行联合学习的训练,因而同一时间连接的device其实bias很大,比如同一地区,能完成的轮数在白天和晚上能差别出四倍。
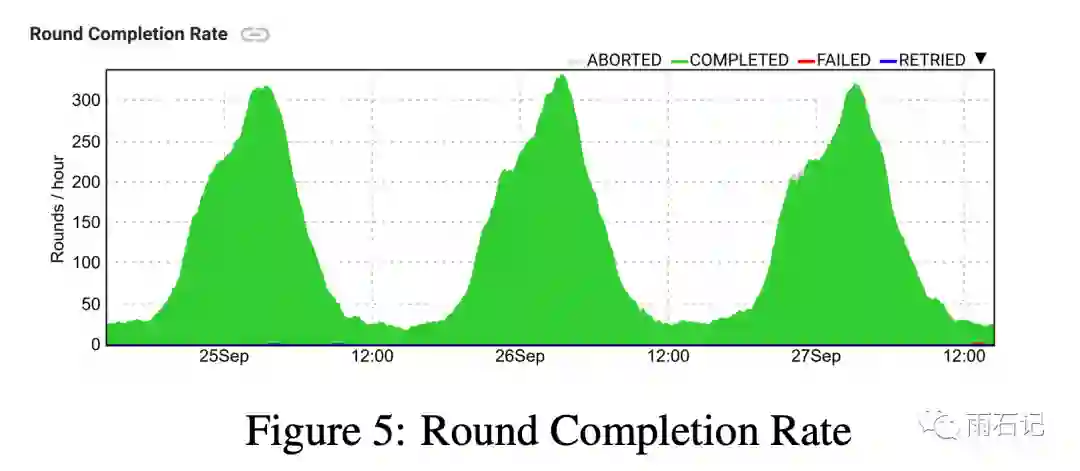
另外,由于训练过程中会有部分device掉线,因而在每轮训练开始之前会选择130%的device数目。
未来要解决的问题
bias
首当其冲的就是bias问题,联合学习假设每个device参与训练的机会相等,但其实不是这样的,有些国家由于基础建设不好可能网络不成,有的国家还处于发展中阶段手机硬件普遍较低所以无法参加训练等等。
目前这个问题只能靠A/B test来解决。如果在某些地方或群体上有metrics的降低,是可以检测出来的。
Convergence time
现在FL一般只能使用数百device同时并行训练,绝大多数的设备都没有处于训练状态,因而收敛速度会比data-center的模式要慢很多。这块希望有能兼容更大并行程度的新算法。
比如,现在选择device和等待device report的时间窗口都是写在配置文件中的,如果能动态的调整就好了,目前一个值得探索的方向是使用一些ML算法去调整这些参数,ML算法的input就是context,比如时区,时间等。
设备调度
现在设备的Multi-Tenancy调度是基于一个简单的队列算法,没有考虑到app的使用频度。对于有些使用不频繁的app,即便调度到FL训练也是在老数据上进行训练,而对于使用频繁的app则没有足够的资源去进行训练。
所以,device上的app之间的bias也要考虑进来。
带宽
对于有些模型的训练,即便device上只有很少的数据,产生的梯度回传可能也要占用大量的带宽。因而,更好的模型压缩技术也是必须的,比如,能不能做量化处理。
联合计算
联合学习只用来训练机器学习的算法,但其他方面的计算也是需要的。因而,可以将联合学习的概念一般化,提出了联合计算的概念,联合计算不仅仅将这个框架限制在Tensorflow + ML这个领域,而是要做成类似移动设备版的Map-Reduce系统,可以兼顾更多的任务。
一个已经在探索的方向是Federated Analytics,可以让我们基于用户device端数据去聚合得到一些有用的统计数据。
参考文献
-
[1]. Bonawitz, Keith, et al. "Towards federated learning at scale: System design." arXiv preprint arXiv:1902.01046 (2019).
由于微信平台算法改版,公号内容将不再以时间排序展示,如果大家想第一时间看到我们的推送,强烈建议星标我们和给我们多点点【在看】。星标具体步骤为:
(1)点击页面最上方"AINLP",进入公众号主页。
(2)点击右上角的小点点,在弹出页面点击“设为星标”,就可以啦。
感谢支持,比心

推荐阅读
征稿启示| 200元稿费+5000DBC(价值20个小时GPU算力)
完结撒花!李宏毅老师深度学习与人类语言处理课程视频及课件(附下载)
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
文本自动摘要任务的“不完全”心得总结番外篇——submodular函数优化
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。

阅读至此了,分享、点赞、在看三选一吧🙏



