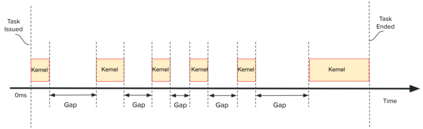
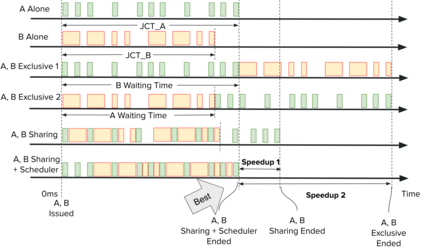
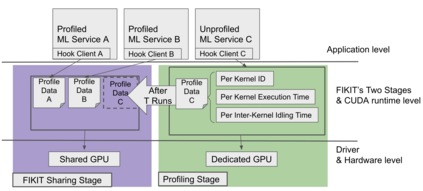
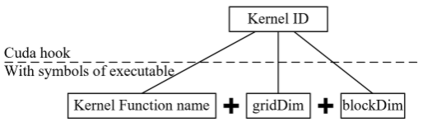
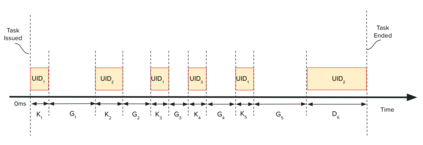
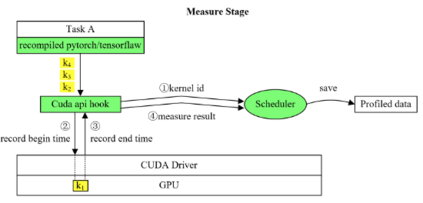
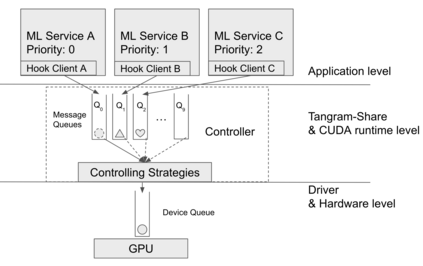
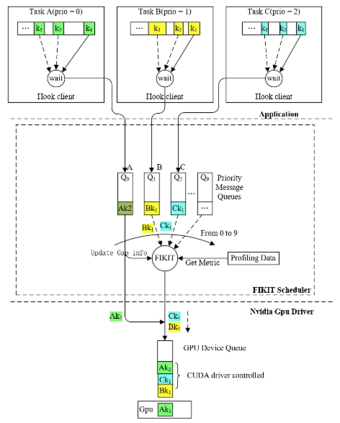
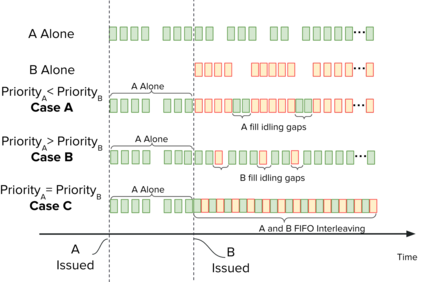
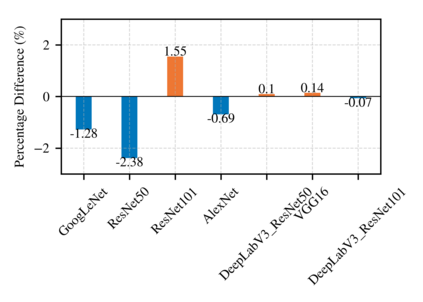
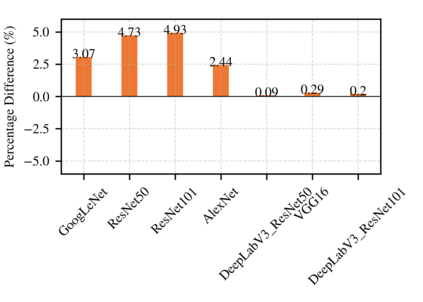
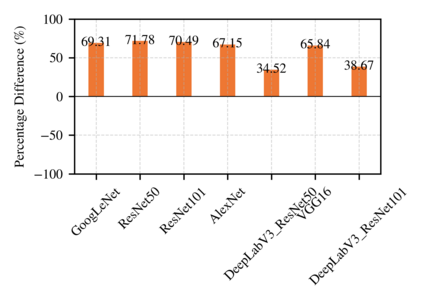
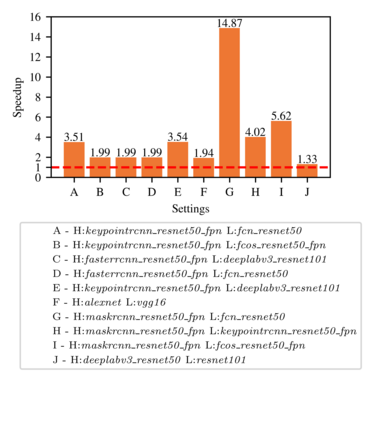
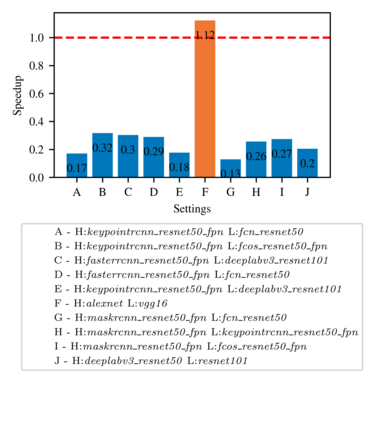
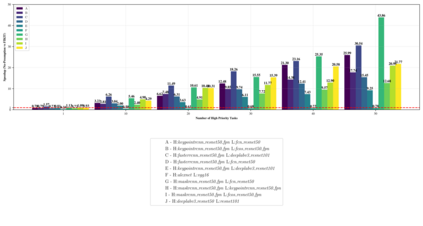
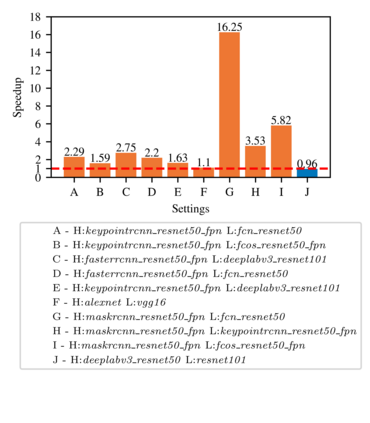
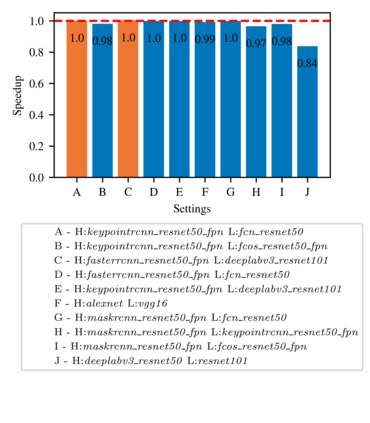
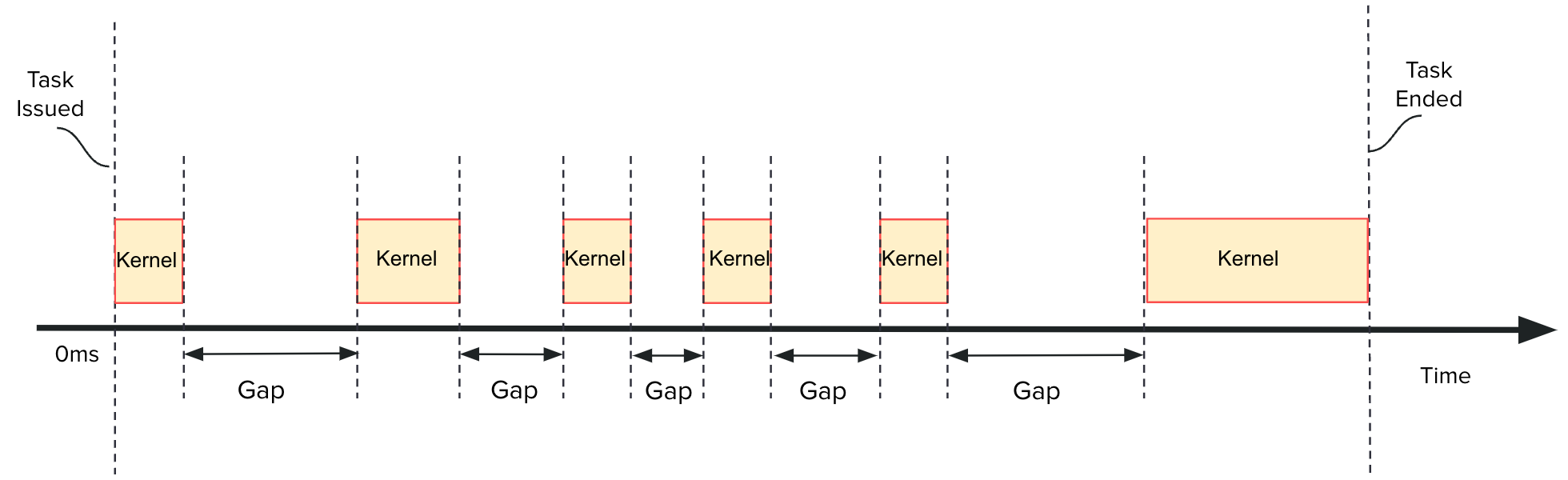
Highly parallelized workloads like machine learning training, inferences and general HPC tasks are greatly accelerated using GPU devices. In a cloud computing cluster, serving a GPU's computation power through multi-tasks sharing is highly demanded since there are always more task requests than the number of GPU available. Existing GPU sharing solutions focus on reducing task-level waiting time or task-level switching costs when multiple jobs competing for a single GPU. Non-stopped computation requests come with different priorities, having non-symmetric impact on QoS for sharing a GPU device. Existing work missed the kernel-level optimization opportunity brought by this setting. To address this problem, we present a novel kernel-level scheduling strategy called FIKIT: Filling Inter-kernel Idle Time. FIKIT incorporates task-level priority information, fine-grained kernel identification, and kernel measurement, allowing low priorities task's execution during high priority task's inter-kernel idle time. Thereby, filling the GPU's device runtime fully, and reduce overall GPU sharing impact to cloud services. Across a set of ML models, the FIKIT based inference system accelerated high priority tasks by 1.33 to 14.87 times compared to the JCT in GPU sharing mode, and more than half of the cases are accelerated by more than 3.5 times. Alternatively, under preemptive sharing, the low-priority tasks have a comparable to default GPU sharing mode JCT, with a 0.84 to 1 times ratio. We further limit the kernel measurement and runtime fine-grained kernel scheduling overhead to less than 5%.
翻译:暂无翻译