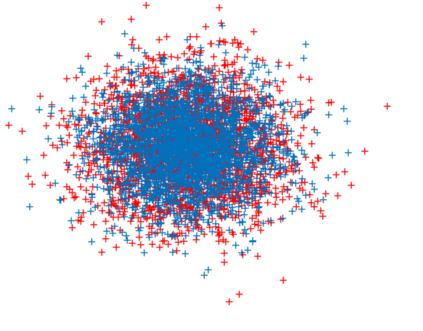
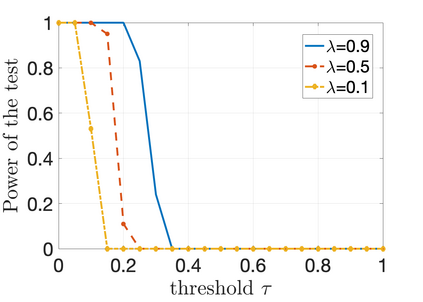
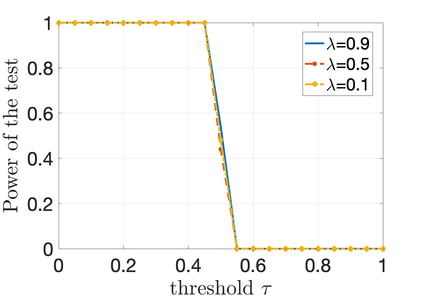
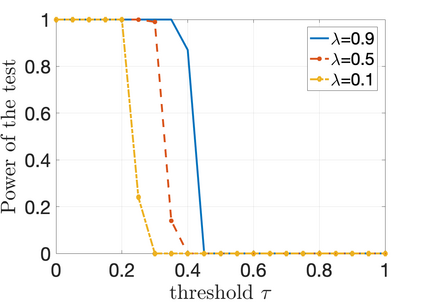
We propose a novel supervised learning method to optimize the kernel in maximum mean discrepancy generative adversarial networks (MMD GANs). Specifically, we characterize a distributionally robust optimization problem to compute a good distribution for the random feature model of Rahimi and Recht to approximate a good kernel function. Due to the fact that the distributional optimization is infinite dimensional, we consider a Monte-Carlo sample average approximation (SAA) to obtain a more tractable finite dimensional optimization problem. We subsequently leverage a particle stochastic gradient descent (SGD) method to solve finite dimensional optimization problems. Based on a mean-field analysis, we then prove that the empirical distribution of the interactive particles system at each iteration of the SGD follows the path of the gradient descent flow on the Wasserstein manifold. We also establish the non-asymptotic consistency of the finite sample estimator. Our empirical evaluation on synthetic data-set as well as MNIST and CIFAR-10 benchmark data-sets indicates that our proposed MMD GAN model with kernel learning indeed attains higher inception scores and lower Fr\`{e}chet inception distances compared to the generative moment matching network (GMMN) and MMD GAN with untrained kernels.
翻译:我们建议一种创新的、监督监督的学习方法,在最大平均差异基因对抗网络(MDGANs)中优化内核优化。具体地说,我们将一个分布强的优化优化问题定性为对Rahimi和Recht随机特征模型的正确分布进行计算,以近似一个良好的内核功能。由于分配优化是无限的,我们考虑蒙特-卡洛样本样本平均近似(SAA),以获得一个更可伸缩的有限尺寸优化问题。我们随后利用粒子蒸汽梯级下降(SGD)方法解决有限尺寸优化问题。根据平均场分析,我们然后证明SGD每次循环的交互式粒子系统的经验分布都遵循瓦塞斯坦柱形梯度下降流路径。我们还建立了有限样品估计器的不依赖一致性。我们对合成数据集以及MNISTI和CIFAR-10基准数据集的实证评估表明,我们提议的MDGAN模型及其内核内核学习确实达到了较高的初始分数和较低的FMLQA的初始距离。我们将GMMM和GMMA与不具有较近的距离。