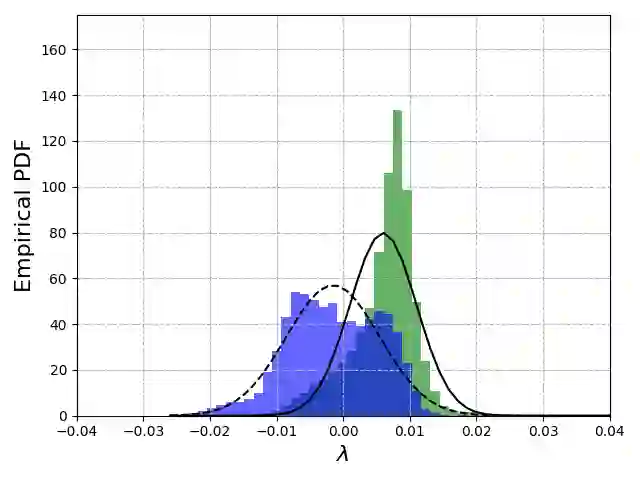
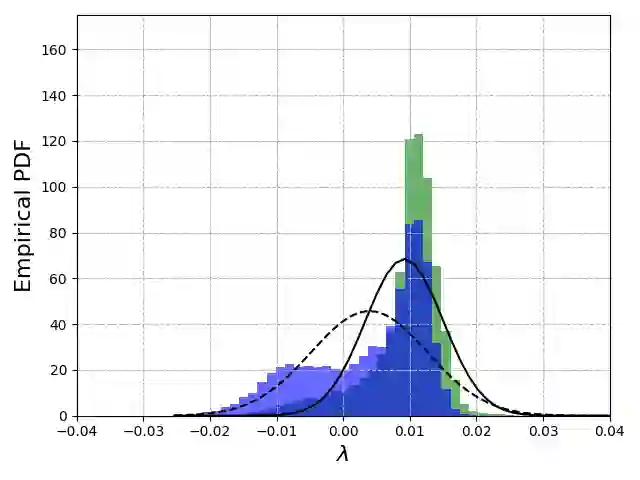
Partial label learning (PLL) is a typical weakly supervised learning, where each sample is associated with a set of candidate labels. The basic assumption of PLL is that the ground-truth label must reside in the candidate set. However, this assumption may not be satisfied due to the unprofessional judgment of the annotators, thus limiting the practical application of PLL. In this paper, we relax this assumption and focus on a more general problem, noisy PLL, where the ground-truth label may not exist in the candidate set. To address this challenging problem, we further propose a novel framework called "Automatic Refinement Network (ARNet)". Our method consists of multiple rounds. In each round, we purify the noisy samples through two key modules, i.e., noisy sample detection and label correction. To guarantee the performance of these modules, we start with warm-up training and automatically select the appropriate correction epoch. Meanwhile, we exploit data augmentation to further reduce prediction errors in ARNet. Through theoretical analysis, we prove that our method is able to reduce the noise level of the dataset and eventually approximate the Bayes optimal classifier. To verify the effectiveness of ARNet, we conduct experiments on multiple benchmark datasets. Experimental results demonstrate that our ARNet is superior to existing state-of-the-art approaches in noisy PLL. Our code will be made public soon.
翻译:部分标签学习( PLL) 是典型的薄弱监管学习( PLL), 每个样本都与一组候选标签相关。 PLL 的基本假设是, 地面真相标签必须包含在候选标签中。 但是, 这一假设可能由于说明者的非专业判断而不能满足, 从而限制了 PLL 的实际应用 。 在本文中, 我们放松这一假设, 并关注一个更普遍的问题, 噪音 PLLL, 候选人组可能不存在地面真相标签 。 为了解决这个具有挑战性的问题, 我们进一步提议了一个新颖的框架, 名为“ 自动精炼网 ” 。 我们的方法由多轮组成。 在每轮中, 我们通过两个关键模块, 即噪音样本检测和标签校正来净化噪音样本。 为了保证这些模块的性能, 我们从热度培训开始, 并自动选择适当的校正。 同时, 我们利用数据增强来进一步减少ARNet 的预测错误 。 通过理论分析, 我们证明我们的方法能够降低数据集的噪音水平, 并最终接近 Bayes 最佳的 Airal grationalalal estal estalestalestalestestal lain.