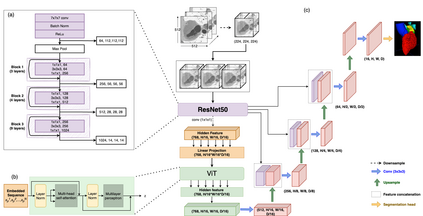
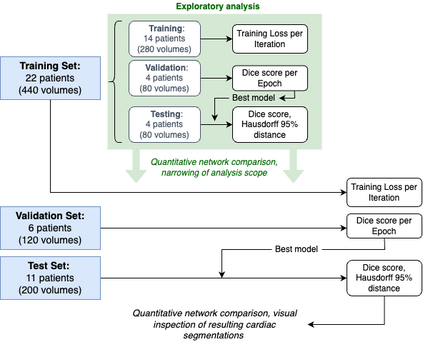
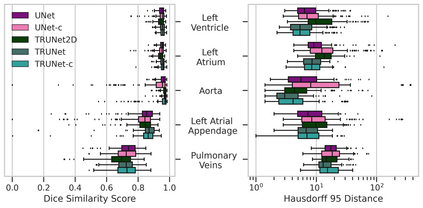
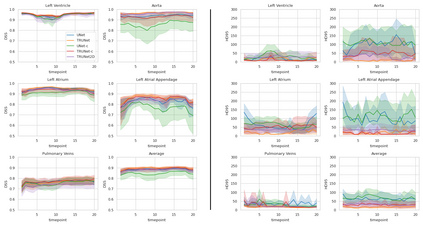
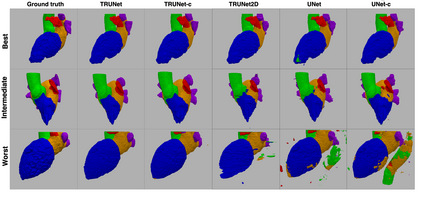
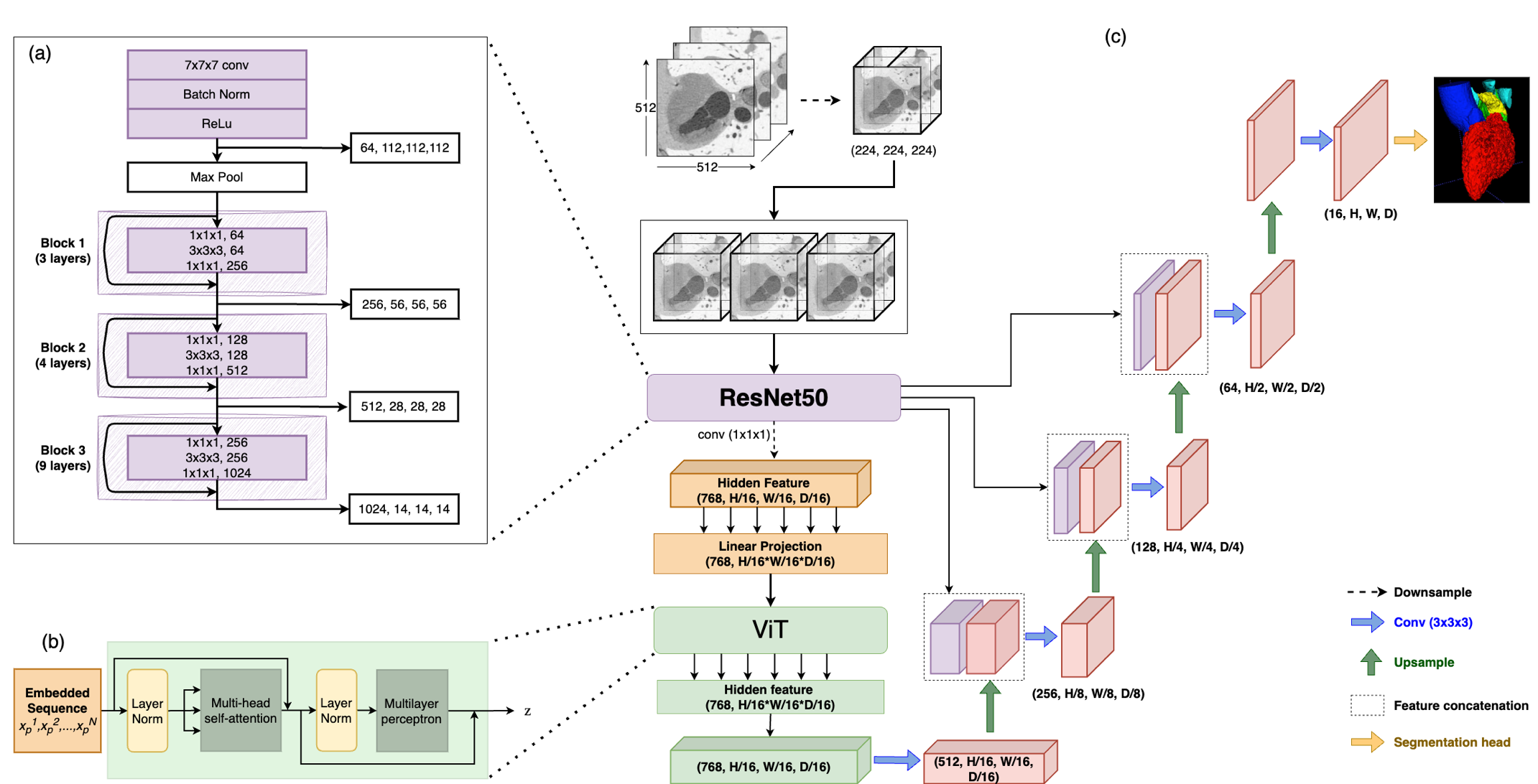
Accurate segmentation of the heart is essential for personalized blood flow simulations and surgical intervention planning. A recent advancement in image recognition is the Vision Transformer (ViT), which expands the field of view to encompass a greater portion of the global image context. We adapted ViT for three-dimensional volume inputs. Cardiac computed tomography (CT) volumes from 39 patients, featuring up to 20 timepoints representing the complete cardiac cycle, were utilized. Our network incorporates a modified ResNet50 block as well as a ViT block and employs cascade upsampling with skip connections. Despite its increased model complexity, our hybrid Transformer-Residual U-Net framework, termed TRUNet, converges in significantly less time than residual U-Net while providing comparable or superior segmentations of the left ventricle, left atrium, left atrial appendage, ascending aorta, and pulmonary veins. TRUNet offers more precise vessel boundary segmentation and better captures the heart's overall anatomical structure compared to residual U-Net, as confirmed by the absence of extraneous clusters of missegmented voxels. In terms of both performance and training speed, TRUNet exceeded U-Net, a commonly used segmentation architecture, making it a promising tool for 3D semantic segmentation tasks in medical imaging. The code for TRUNet is available at github.com/ljollans/TRUNet.
翻译:暂无翻译