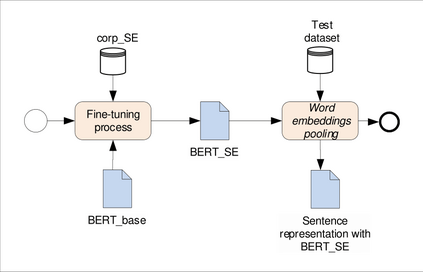
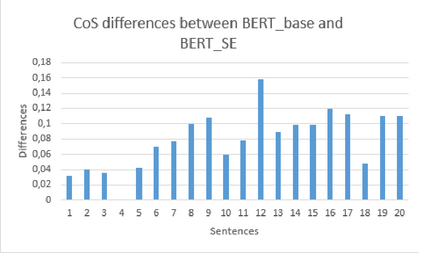
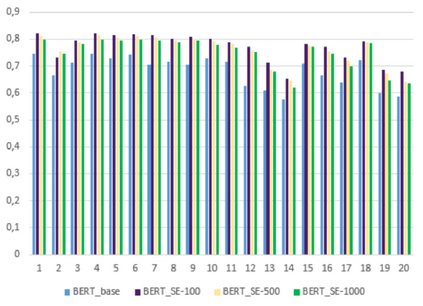
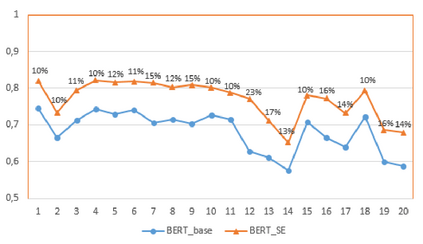
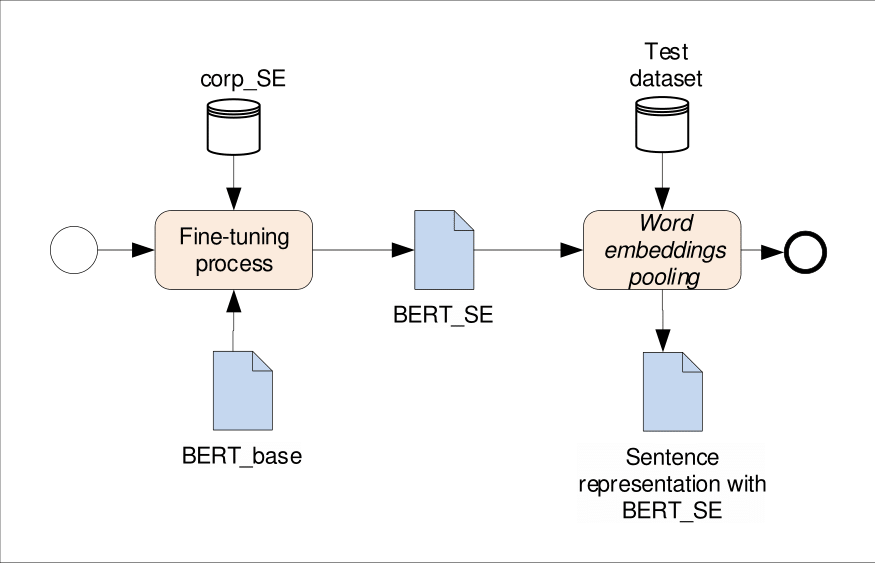
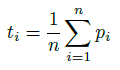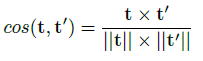The application of Natural Language Processing (NLP) has achieved a high level of relevance in several areas. In the field of software engineering (SE), NLP applications are based on the classification of similar texts (e.g. software requirements), applied in tasks of estimating software effort, selection of human resources, etc. Classifying software requirements has been a complex task, considering the informality and complexity inherent in the texts produced during the software development process. The pre-trained embedding models are shown as a viable alternative when considering the low volume of textual data labeled in the area of software engineering, as well as the lack of quality of these data. Although there is much research around the application of word embedding in several areas, to date, there is no knowledge of studies that have explored its application in the creation of a specific model for the domain of the SE area. Thus, this article presents the proposal for a contextualized embedding model, called BERT_SE, which allows the recognition of specific and relevant terms in the context of SE. The assessment of BERT_SE was performed using the software requirements classification task, demonstrating that this model has an average improvement rate of 13% concerning the BERT_base model, made available by the authors of BERT. The code and pre-trained models are available at https://github.com/elianedb.
翻译:应用自然语言处理(NLP)在几个领域具有高度的相关性。在软件工程(SE)领域,国家语言应用基于类似文字的分类(如软件要求),用于估算软件努力量、人力资源选择等任务。考虑到软件开发过程中产生的文本具有非正式性和复杂性,对软件要求进行分类是一项复杂的任务。考虑到软件开发过程中产生的文本具有非正式性和复杂性,预先培训的嵌入模型在几个领域具有高度的相关性,在考虑软件工程领域标注的文本数据数量少以及这些数据缺乏质量时,显示预先培训的嵌入模型是一个可行的替代方法。尽管迄今为止,围绕将文字嵌入若干领域的应用进行了大量研究(如软件要求),但对于在为SE领域领域创建具体模型方面探索应用软件要求的研究结果还很复杂。因此,本文章提出了一个背景化嵌入模型提案,称为BERT_SE, 允许在SEE中承认具体和相关的术语。BERT_SEEE评估是利用软件要求分类任务进行的,表明这一模型在BERB/BAR/BBSBBBBSBSBSBSBSBSBSBSBSBSBBBBBBSBBBBBBBBBBSBSBSBBBBBBSBBSBSBSBSBSBBBBBSBSBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBB