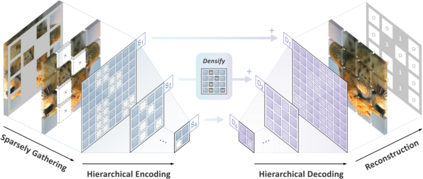
We identify and overcome two key obstacles in extending the success of BERT-style pre-training, or the masked image modeling, to convolutional networks (convnets): (i) convolution operation cannot handle irregular, random-masked input images; (ii) the single-scale nature of BERT pre-training is inconsistent with convnet's hierarchical structure. For (i), we treat unmasked pixels as sparse voxels of 3D point clouds and use sparse convolution to encode. This is the first use of sparse convolution for 2D masked modeling. For (ii), we develop a hierarchical decoder to reconstruct images from multi-scale encoded features. Our method called Sparse masKed modeling (SparK) is general: it can be used directly on any convolutional model without backbone modifications. We validate it on both classical (ResNet) and modern (ConvNeXt) models: on three downstream tasks, it surpasses both state-of-the-art contrastive learning and transformer-based masked modeling by similarly large margins (around +1.0%). Improvements on object detection and instance segmentation are more substantial (up to +3.5%), verifying the strong transferability of features learned. We also find its favorable scaling behavior by observing more gains on larger models. All this evidence reveals a promising future of generative pre-training on convnets. Codes and models are released at https://github.com/keyu-tian/SparK.
翻译:我们发现并克服了将BERT式预培训成功率或蒙面图像模型成功率扩大到 convolual 网络(convnets)的两大障碍:(一) 熔化操作无法处理非常规的、随机伪造的输入图像;(二) BERT预培训的单一规模性质与 convnet 的等级结构不相符。 对于 (一) 我们把无包装像做为3D点云的稀疏的 voxels, 并使用稀薄的混凝土编码。 这是为 2D 掩面模型首次使用稀释的混凝土。 对于 (二) 我们开发了一个等级解码器, 以从多尺度编码的特性重建图像。 我们称为 Sprass MASKed 模型(SparK) 是一般性的: 它可以直接用于任何卷动模型, 而无需修改骨架结构结构结构结构结构结构结构结构结构。 我们验证它为传统(ResNet) 和现代(CONNEXt) 模式: 在三个下游任务中, 它超过了状态的对比学习和变换式模型。