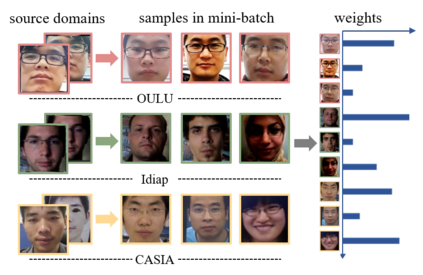
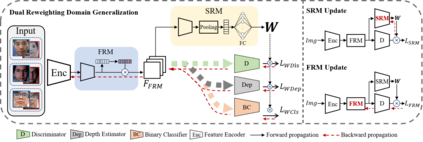
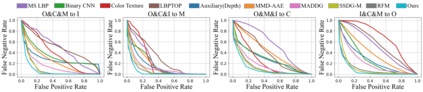
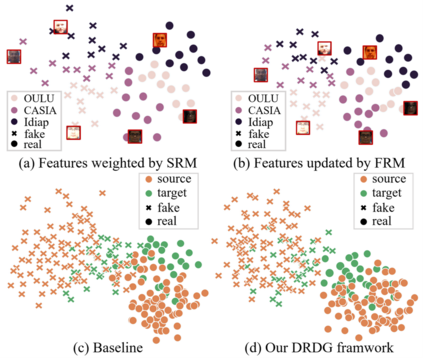
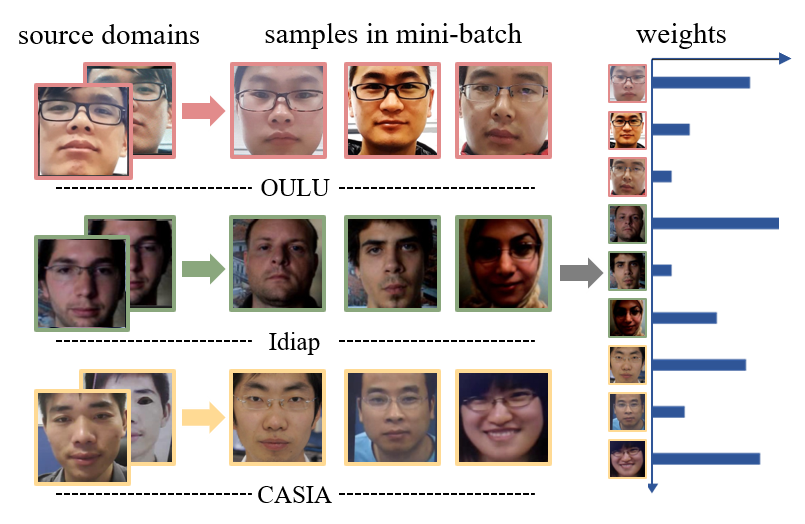
Face anti-spoofing approaches based on domain generalization (DG) have drawn growing attention due to their robustness for unseen scenarios. Previous methods treat each sample from multiple domains indiscriminately during the training process, and endeavor to extract a common feature space to improve the generalization. However, due to complex and biased data distribution, directly treating them equally will corrupt the generalization ability. To settle the issue, we propose a novel Dual Reweighting Domain Generalization (DRDG) framework which iteratively reweights the relative importance between samples to further improve the generalization. Concretely, Sample Reweighting Module is first proposed to identify samples with relatively large domain bias, and reduce their impact on the overall optimization. Afterwards, Feature Reweighting Module is introduced to focus on these samples and extract more domain-irrelevant features via a self-distilling mechanism. Combined with the domain discriminator, the iteration of the two modules promotes the extraction of generalized features. Extensive experiments and visualizations are presented to demonstrate the effectiveness and interpretability of our method against the state-of-the-art competitors.
翻译:以往的方法在培训过程中不分青红皂白地对待来自多个领域的样本,并努力提取一个共同的特征空间来改进一般化。然而,由于数据分布复杂和有偏差,直接处理这些样本同样会腐蚀一般化能力。为了解决这个问题,我们提议了一个新型的双重再加权通用(DRDG)框架,对样本之间的相对重要性进行迭接性再加权,以进一步改进一般化。具体地说,抽样再加权模块首先提出发现具有相对大域偏差的样本,并减少其对总体优化的影响。随后,引入了特征再加权模块,侧重于这些样本,并通过自我蒸馏机制提取更多与域相关的特征。结合了域区分器,两个模块的循环促进了普遍特征的提取。介绍了广泛的实验和可视化,以证明我们的方法对最先进的竞争者的有效性和可解释性。