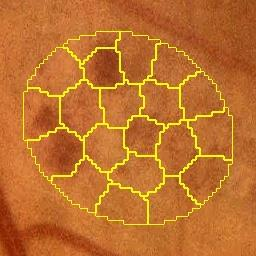
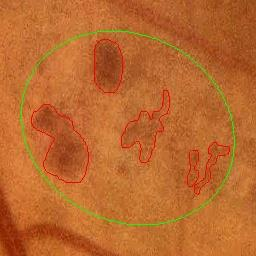
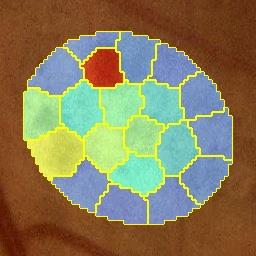
Deep-learning-based approaches for retinal lesion segmentation often require an abundant amount of precise pixel-wise annotated data. However, coarse annotations such as circles or ellipses for outlining the lesion area can be six times more efficient than pixel-level annotation. Therefore, this paper proposes an annotation refinement network to convert a coarse annotation into a pixel-level segmentation mask. Our main novelty is the application of the prototype learning paradigm to enhance the generalization ability across different datasets or types of lesions. We also introduce a prototype weighing module to handle challenging cases where the lesion is overly small. The proposed method was trained on the publicly available IDRiD dataset and then generalized to the public DDR and our real-world private datasets. Experiments show that our approach substantially improved the initial coarse mask and outperformed the non-prototypical baseline by a large margin. Moreover, we demonstrate the usefulness of the prototype weighing module in both cross-dataset and cross-class settings.
翻译:对视网膜损伤分解的深学习方法往往需要大量精确的像素说明数据。然而,圆形或椭圆等粗略说明概述损害区比像素级注解效率高六倍于像素级注解。因此,本文件建议建立一个批注性改进网络,将粗略注解转换成像素级分解面罩。我们的主要新颖之处是应用原型学习模式,提高不同数据集或不同类型损伤的概括性能力。我们还引入一个原型称模块,在病变过小的情况下处理具有挑战性的个案。拟议方法在公开提供的IDRID数据集上进行了培训,然后推广到公众解甲返乡和我们真实世界的私人数据集。实验表明,我们的方法大大改进了最初的粗口罩,大大超越了非protodic基线。此外,我们还展示了原型称称称模块在交叉数据集和跨类环境中的效用。