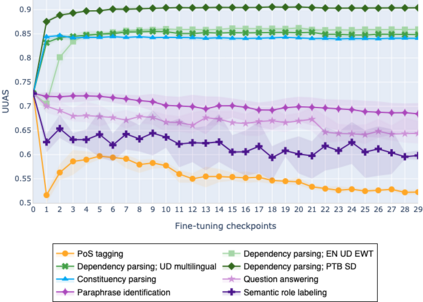
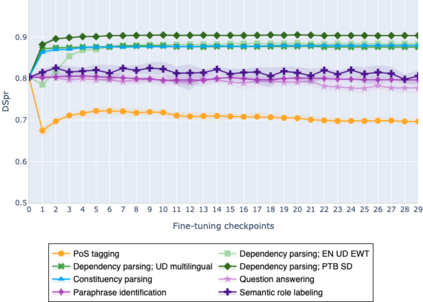
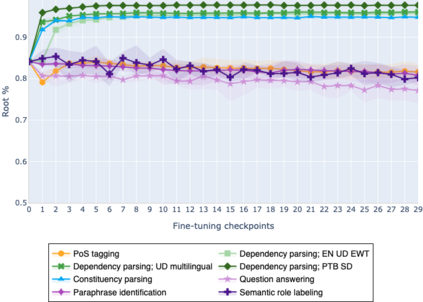
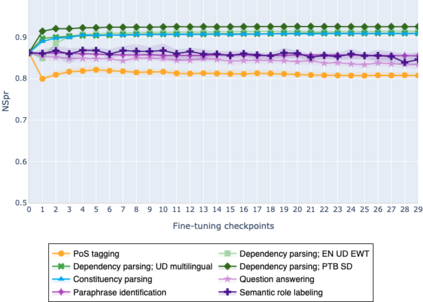
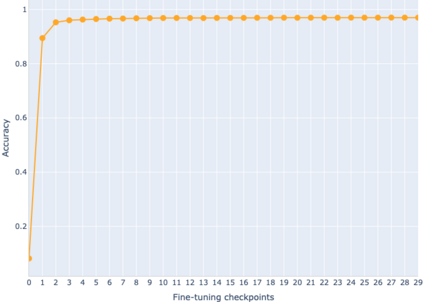
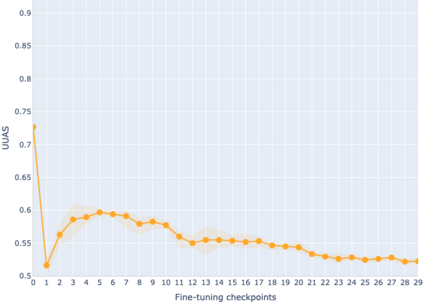
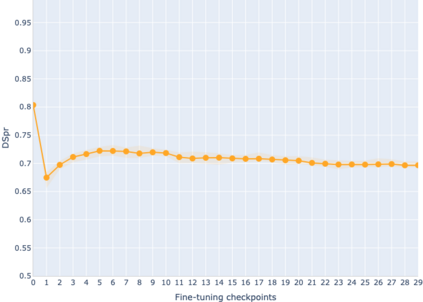
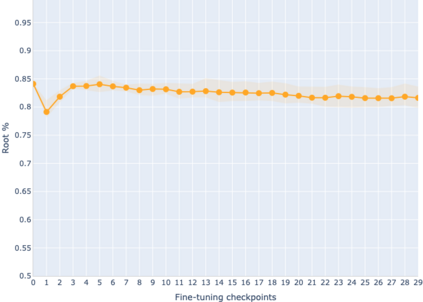
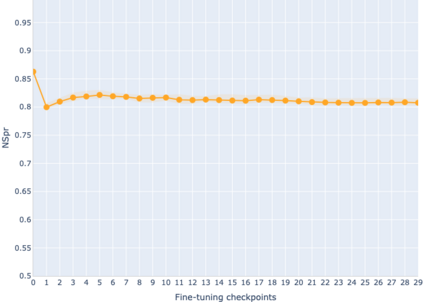
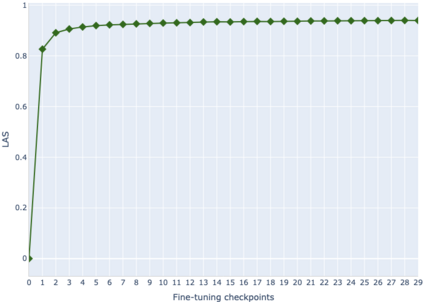
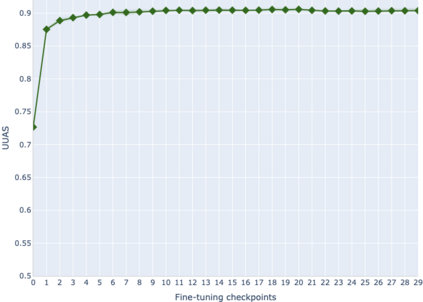
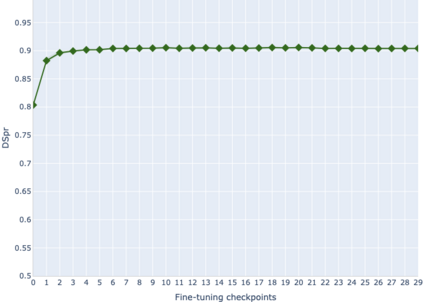
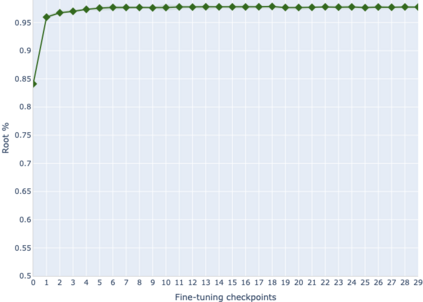
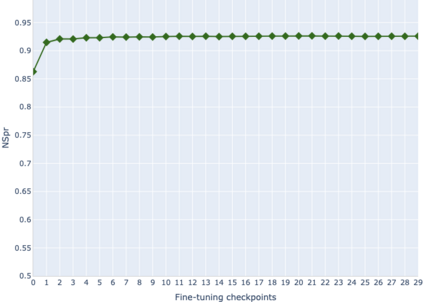
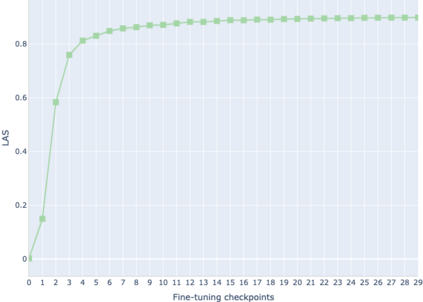
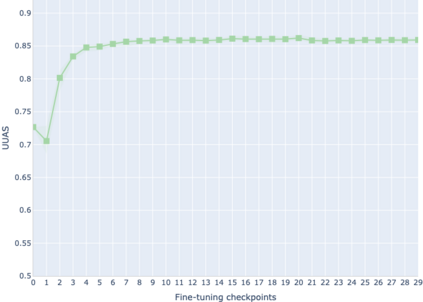
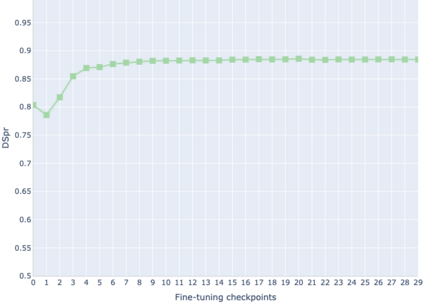
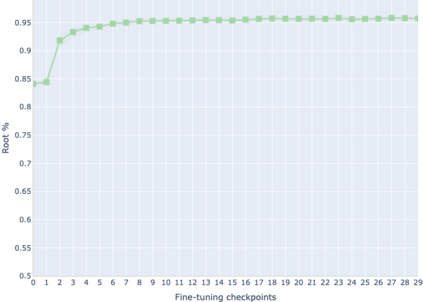
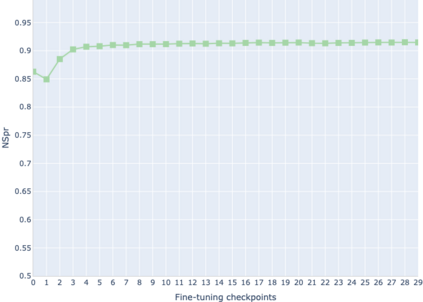
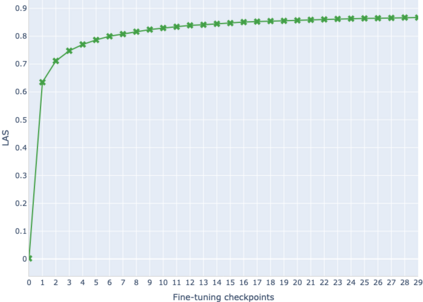
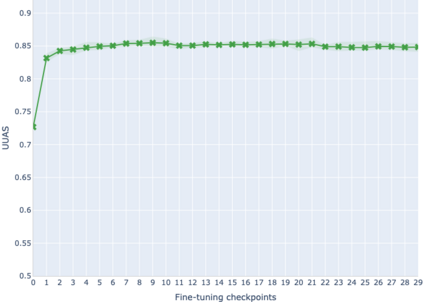
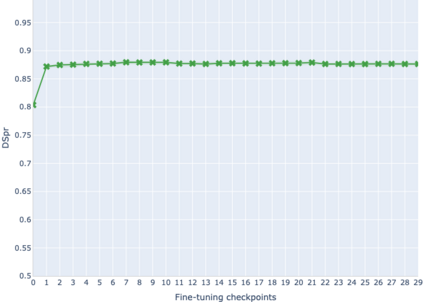
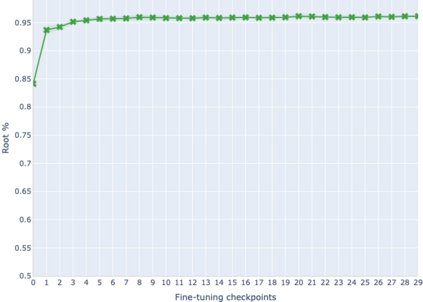
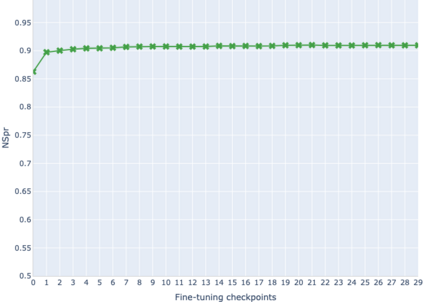
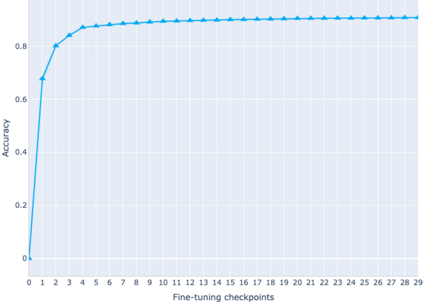
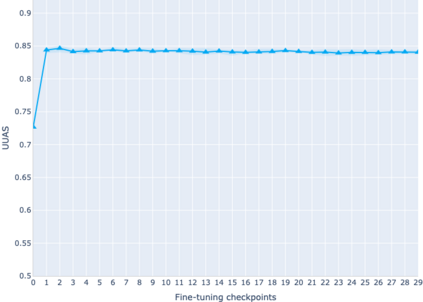
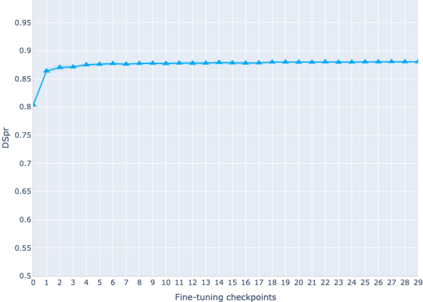
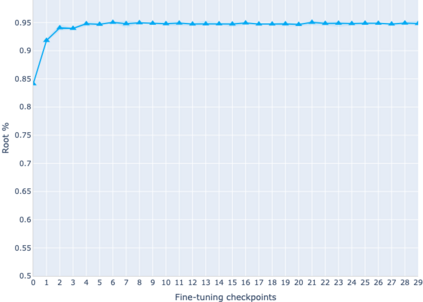
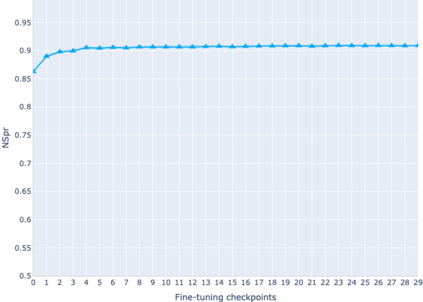
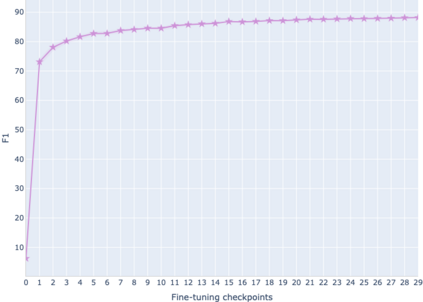
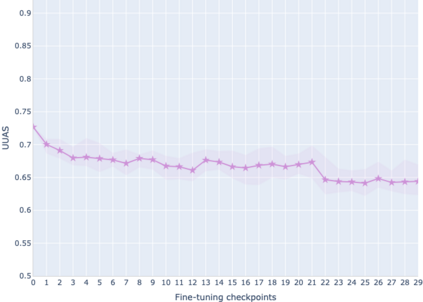
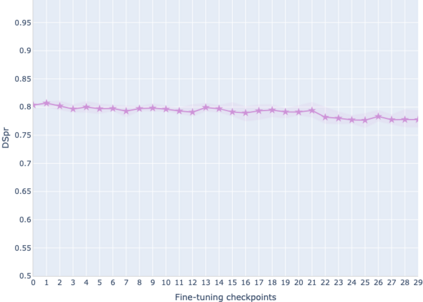
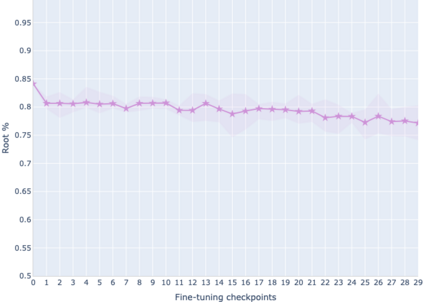
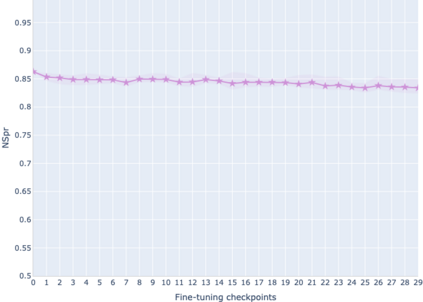
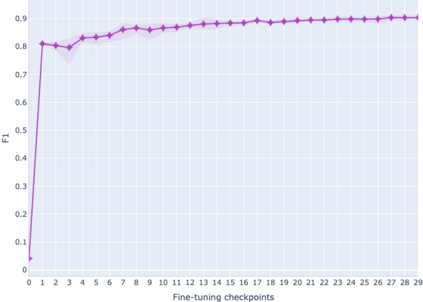
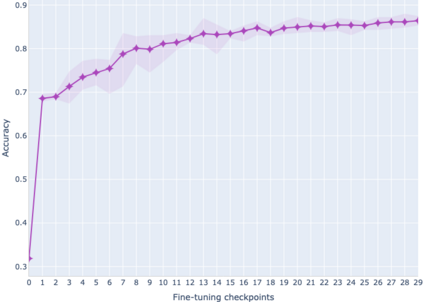
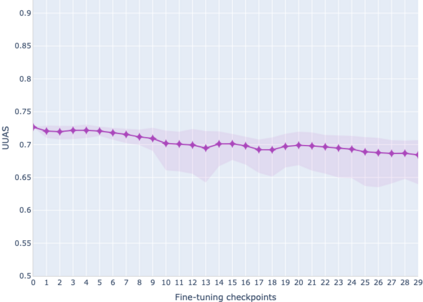
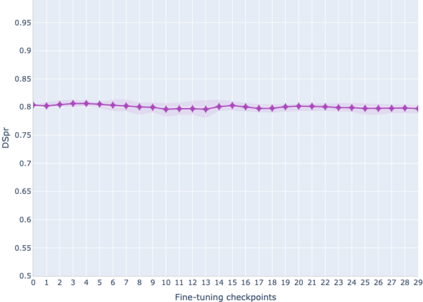
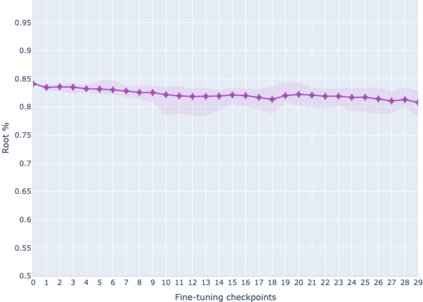
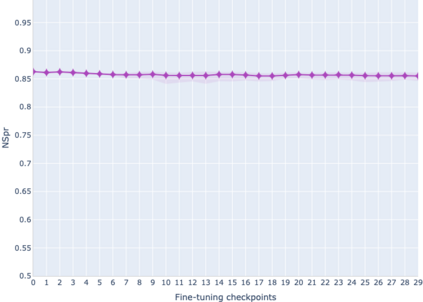
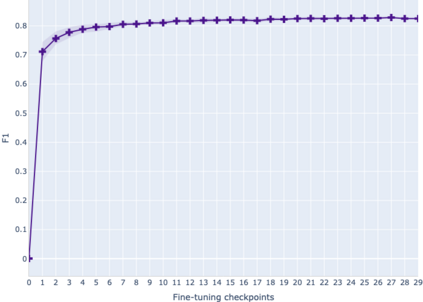
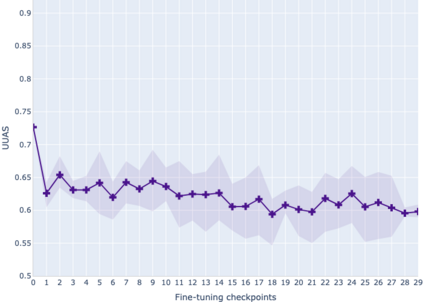
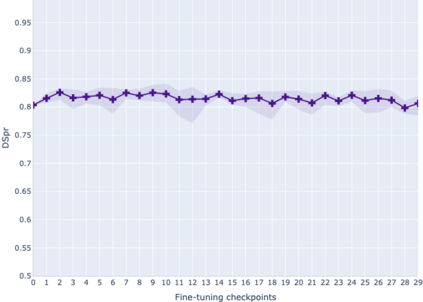
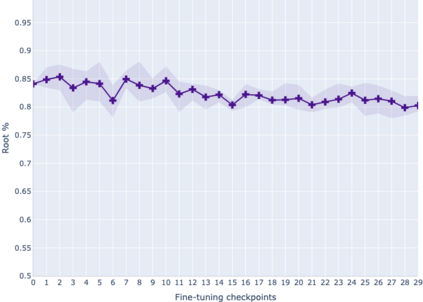
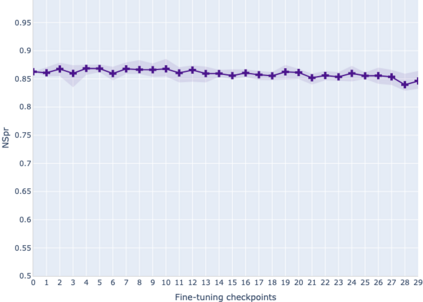
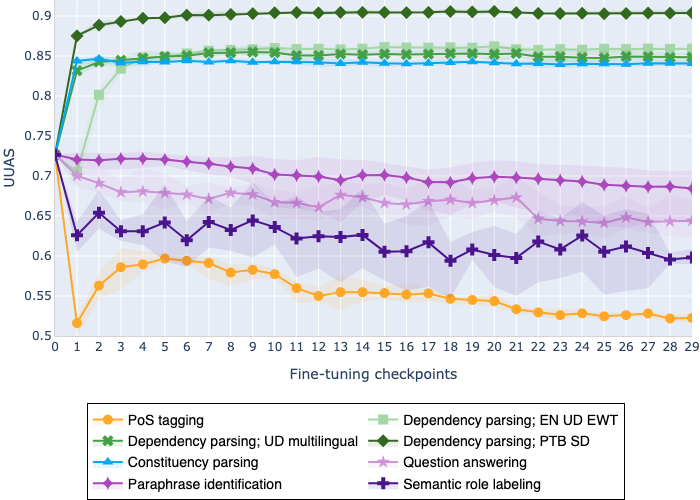
The adaptation of pretrained language models to solve supervised tasks has become a baseline in NLP, and many recent works have focused on studying how linguistic information is encoded in the pretrained sentence representations. Among other information, it has been shown that entire syntax trees are implicitly embedded in the geometry of such models. As these models are often fine-tuned, it becomes increasingly important to understand how the encoded knowledge evolves along the fine-tuning. In this paper, we analyze the evolution of the embedded syntax trees along the fine-tuning process of BERT for six different tasks, covering all levels of the linguistic structure. Experimental results show that the encoded syntactic information is forgotten (PoS tagging), reinforced (dependency and constituency parsing) or preserved (semantics-related tasks) in different ways along the fine-tuning process depending on the task.
翻译:对经过培训的语言模型进行调整以解决受监督的任务已成为国家劳工政策的一个基线,许多近期工作的重点是研究语言信息如何在经过培训的句子表述中编码,除其他信息外,还表明整个语法树都隐含在这类模型的几何中。由于这些模型往往经过微调,因此越来越重要的是要了解编码知识如何随着微调而演变。在本文件中,我们分析了嵌入的语法树的演变情况,沿BERT的微调过程对六项不同任务进行演变,涵盖语言结构的所有层面。实验结果显示,编码的合成信息被遗忘(POS标记)、强化(依赖性和选区划分)或保存(与语法有关的任务),其方式不同,视任务而定。