
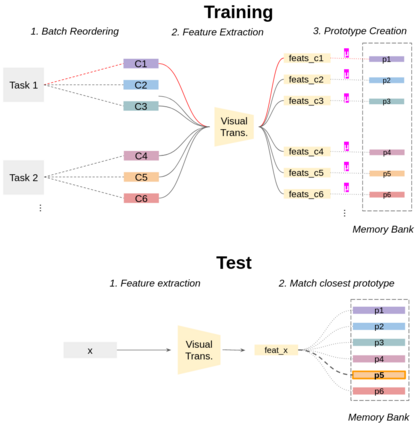
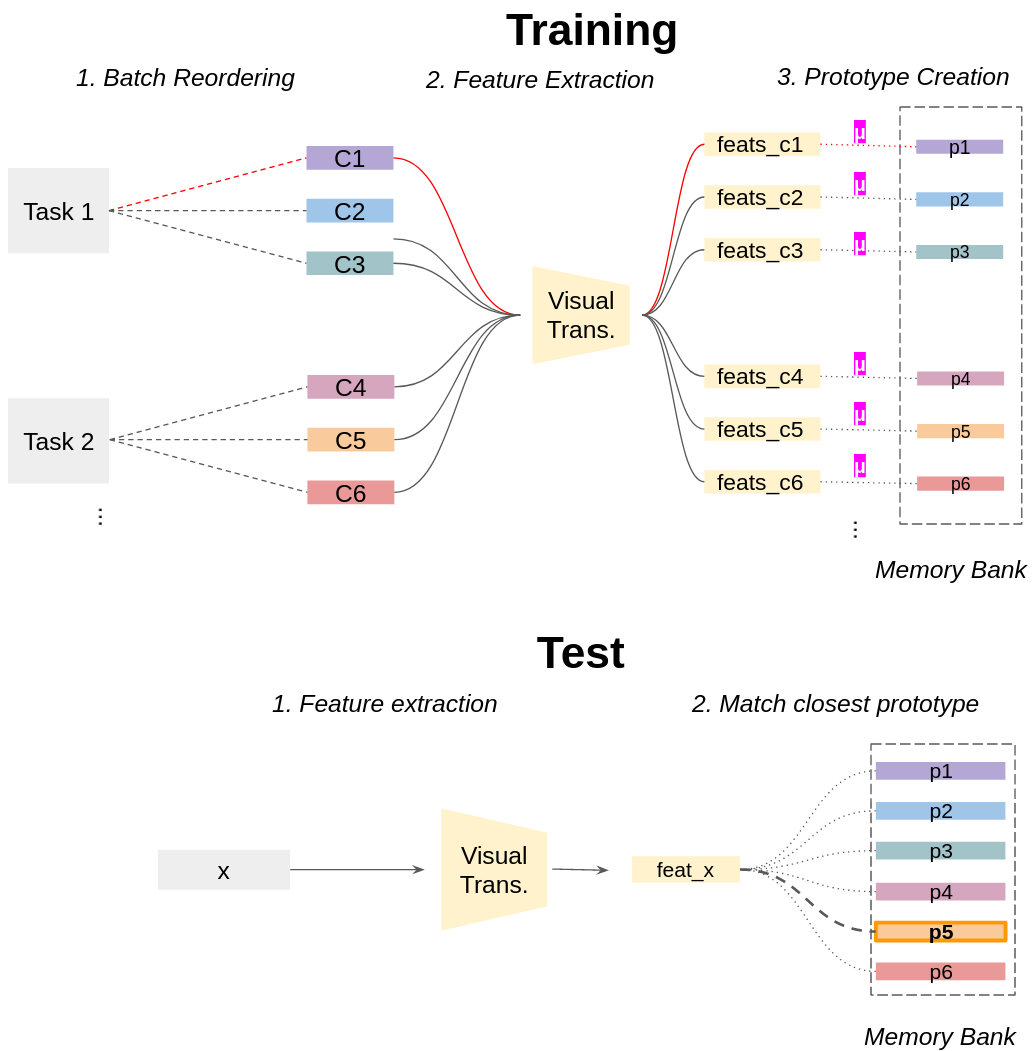
In this short paper, we propose a baseline (off-the-shelf) for Continual Learning of Computer Vision problems, by leveraging the power of pretrained models. By doing so, we devise a simple approach achieving strong performance for most of the common benchmarks. Our approach is fast since requires no parameters updates and has minimal memory requirements (order of KBytes). In particular, the "training" phase reorders data and exploit the power of pretrained models to compute a class prototype and fill a memory bank. At inference time we match the closest prototype through a knn-like approach, providing us the prediction. We will see how this naive solution can act as an off-the-shelf continual learning system. In order to better consolidate our results, we compare the devised pipeline with common CNN models and show the superiority of Vision Transformers, suggesting that such architectures have the ability to produce features of higher quality. Moreover, this simple pipeline, raises the same questions raised by previous works \cite{gdumb} on the effective progresses made by the CL community especially in the dataset considered and the usage of pretrained models. Code is live at https://github.com/francesco-p/off-the-shelf-cl
翻译:在这份简短的文件中,我们通过利用预先培训的模型的力量,提出了计算机视觉问题持续学习的基线(现成),以利用预先培训的模型的力量,为计算机视觉问题持续学习提供一个基准(现成),通过这样做,我们设计了一个简单的方法,使大多数共同基准取得强劲的绩效。我们的方法是快速的,因为不需要更新参数,并且有最低的记忆要求(KBytes的顺序)。特别是,“训练”阶段重新订购数据并利用预先培训的模型的力量来计算一个类原型并填充记忆库。在推断时,我们通过类似 knn 的方法匹配最接近的原型,为我们提供预测。我们将看到这种天真的解决方案如何能成为现成的不断学习系统。为了更好地巩固我们的成果,我们把设计的管道与普通CNN模型进行比较,并展示视野变异者的优势,表明这种结构有能力产生更高品质的特征。此外,这种简单的管道提出了以前作品\cite{gdumbb}就CL社区特别是在考虑的数据设置和使用预先培训的模型方面所取得的有效进展所提出的同样的问题。
相关内容

Source: Apple - iOS 8

