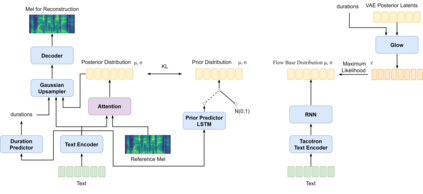
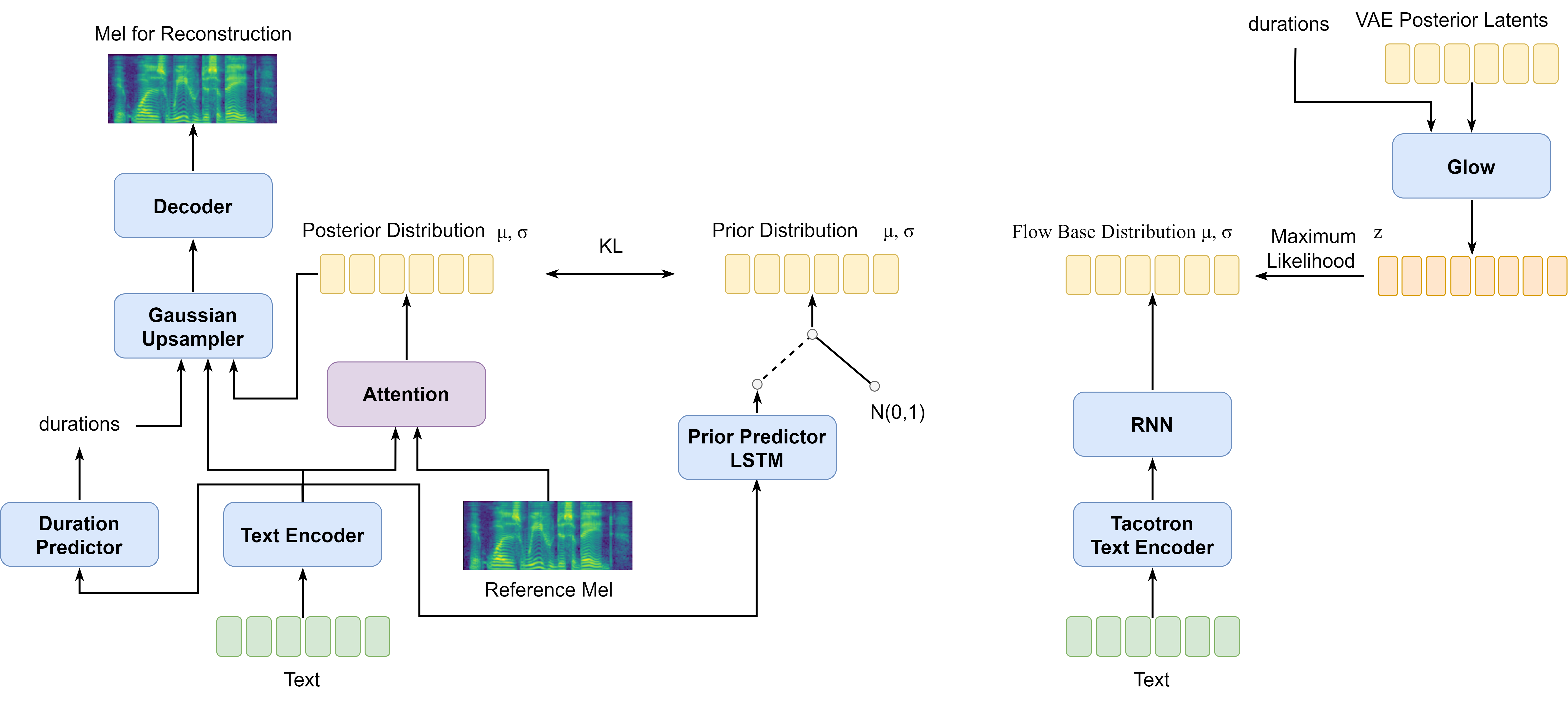
A large part of the expressive speech synthesis literature focuses on learning prosodic representations of the speech signal which are then modeled by a prior distribution during inference. In this paper, we compare different prior architectures at the task of predicting phoneme level prosodic representations extracted with an unsupervised FVAE model. We use both subjective and objective metrics to show that normalizing flow based prior networks can result in more expressive speech at the cost of a slight drop in quality. Furthermore, we show that the synthesized speech has higher variability, for a given text, due to the nature of normalizing flows. We also propose a Dynamical VAE model, that can generate higher quality speech although with decreased expressiveness and variability compared to the flow based models.
翻译:表达式语音合成文献的很大一部分侧重于学习对语音信号的预言表达,然后在推断期间以先前的分布为模型。在本文中,我们比较了先前的不同结构,以预测用不受监督的FVAE模型提取的电话层预言表达方式。我们使用主观和客观的衡量尺度来表明,以先前网络为基础的正常化可以导致以质量略微下降为代价的更清晰的表达式。此外,我们表明,合成的语音具有较高的变异性,对于某一文本,由于流动的正常性质。我们还提出了动态VAE模型,该模型可以产生更高质量的表达方式,尽管与以流动为基础的模型相比,其表达性和变异性会减少。