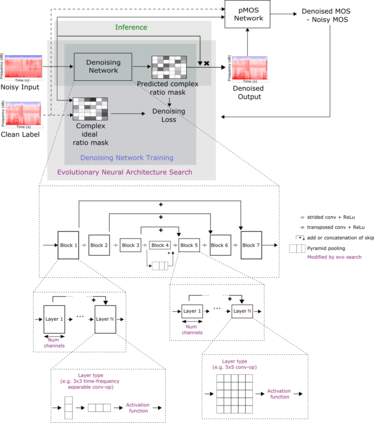
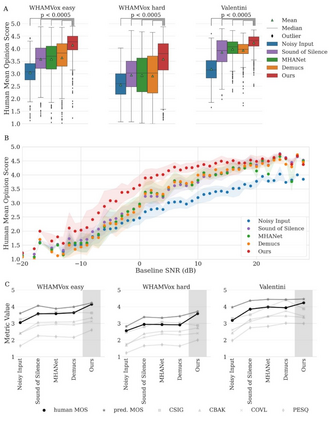
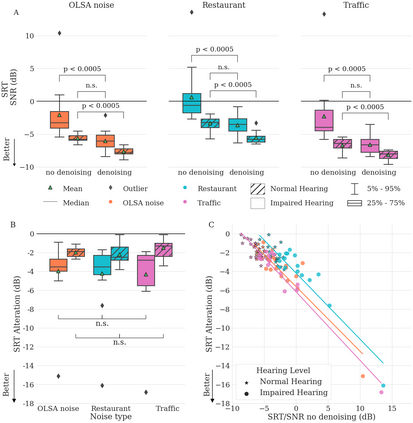
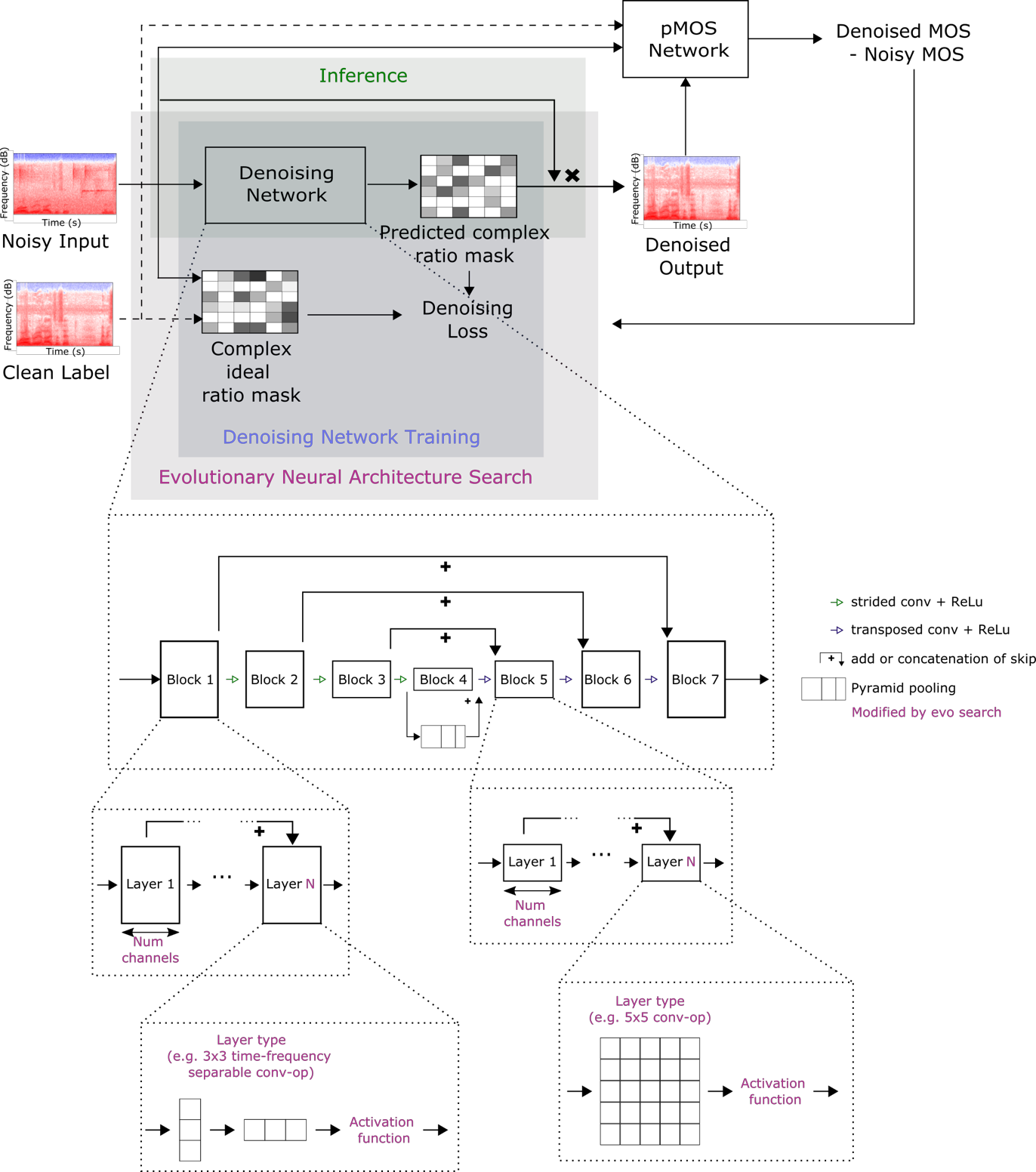
Almost half a billion people world-wide suffer from disabling hearing loss. While hearing aids can partially compensate for this, a large proportion of users struggle to understand speech in situations with background noise. Here, we present a deep learning-based algorithm that selectively suppresses noise while maintaining speech signals. The algorithm restores speech intelligibility for hearing aid users to the level of control subjects with normal hearing. It consists of a deep network that is trained on a large custom database of noisy speech signals and is further optimized by a neural architecture search, using a novel deep learning-based metric for speech intelligibility. The network achieves state-of-the-art denoising on a range of human-graded assessments, generalizes across different noise categories and - in contrast to classic beamforming approaches - operates on a single microphone. The system runs in real time on a laptop, suggesting that large-scale deployment on hearing aid chips could be achieved within a few years. Deep learning-based denoising therefore holds the potential to improve the quality of life of millions of hearing impaired people soon.
翻译:全世界近5亿人口遭受了听力丧失的残疾。 虽然助听器可以部分地弥补这一点, 大部分用户在背景噪音的情况下很难理解语言。 在这里, 我们展示了一种深层次的基于学习的算法,在保持语音信号的同时有选择地抑制噪音。 算法将助听使用者的语音智能恢复到正常听力控制主题的水平。 它包括一个深层次的网络,在庞大的语音信号定制数据库上接受培训,并通过神经结构搜索进一步优化,使用新的深层次的基于学习的语音智能指标。 网络在一系列人类级别的评估中实现了最先进的分层分层,对不同的噪音类别进行了概括化,并与典型的模范组合方法相反,在单一的麦克风上运作。 系统实时运行在一台手提电脑上,建议可以在几年内大规模部署助听器芯片。 因此, 深层次的分层分解可以很快提高数百万听力受损的人的生活质量。