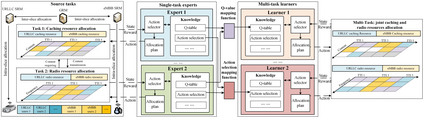
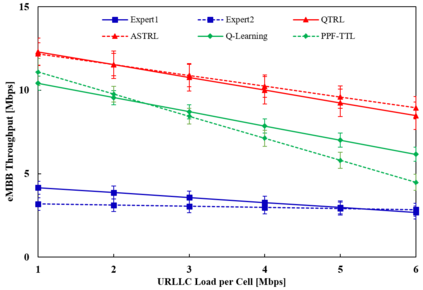
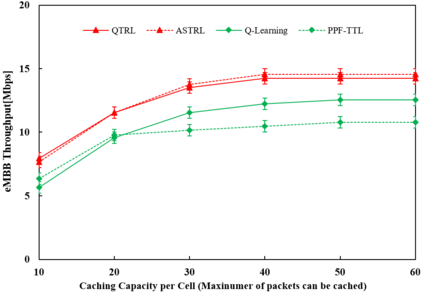
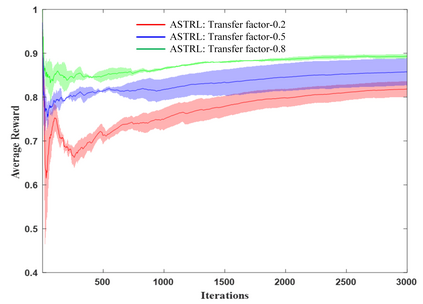
Radio access network (RAN) slicing is an important part of network slicing in 5G. The evolving network architecture requires the orchestration of multiple network resources such as radio and cache resources. In recent years, machine learning (ML) techniques have been widely applied for network slicing. However, most existing works do not take advantage of the knowledge transfer capability in ML. In this paper, we propose a transfer reinforcement learning (TRL) scheme for joint radio and cache resources allocation to serve 5G RAN slicing.We first define a hierarchical architecture for the joint resources allocation. Then we propose two TRL algorithms: Q-value transfer reinforcement learning (QTRL) and action selection transfer reinforcement learning (ASTRL). In the proposed schemes, learner agents utilize the expert agents' knowledge to improve their performance on target tasks. The proposed algorithms are compared with both the model-free Q-learning and the model-based priority proportional fairness and time-to-live (PPF-TTL) algorithms. Compared with Q-learning, QTRL and ASTRL present 23.9% lower delay for Ultra Reliable Low Latency Communications slice and 41.6% higher throughput for enhanced Mobile Broad Band slice, while achieving significantly faster convergence than Q-learning. Moreover, 40.3% lower URLLC delay and almost twice eMBB throughput are observed with respect to PPF-TTL.
翻译:正在演变的网络架构要求调试多种网络资源,例如无线电和缓冲资源。近年来,机器学习(ML)技术被广泛应用于网络切片。然而,大多数现有工作并未利用ML的知识转让能力。 在本文件中,我们提议了一个转让强化学习(TRL)计划,用于联合无线电和缓冲资源分配,以服务5G RAN剪片。我们首先为联合资源分配确定等级结构。然后,我们提议两个TRL算法:Q值转让强化学习(QTRL)和行动选择转让强化学习(ASTOL)。在拟议办法中,学习者利用专家人员的知识来提高他们在目标任务上的业绩。在拟议算法中,我们建议采用一个转让强化学习(TRL)计划,用于联合无线电和缓冲资源分配(PPF-TUP)联合分配。我们首先为联合资源分配确定了一个等级结构结构架构。然后,我们提出了两个TRL算法:Q-价值转移强化强化学习学习(QTRL)和ASTL(ER)两种算法方法:Q-RV-L-CFML 更快的延迟度,同时实现超低水平的升级的升级的升级的升级的升级的升级和升级的升级的升级的升级。3.3%的升级的升级的升级的升级的升级,同时实现的升级的升级的升级的升级的升级的升级的升级和升级的升级的升级的升级的升级的升级的升级的升级的升级的升级的升级的升级的升级的升级的升级的升级的升级的升级的升级的升级的升级的升级的升级的升级的升级的升级的升级的升级的升级的升级的升级的升级的升级的升级的升级的升级的升级的升级的升级的升级的升级的升级的升级的升级的升级的升级的升级的升级的升级的升级的升级的升级的升级的升级的升级的升级的升级的升级的升级的升级的升级的升级的升级的升级的升级的升级的升级的升级的升级的升级的升级的升级的升级的升级的升级的升级的升级的升级的升级的升级的升级的升级的升级的升级的升级的升级的升级的升级的升级的升级的升级的升级的升级的升级的升级的升级的升级的升级的升级的升级的升级的升级的升级的升级的升级的升级