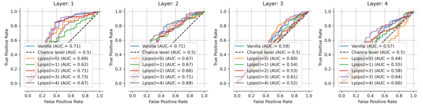
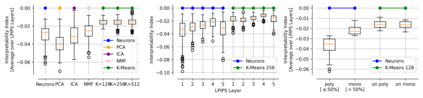
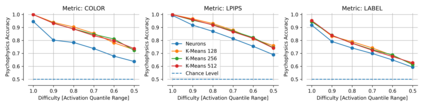
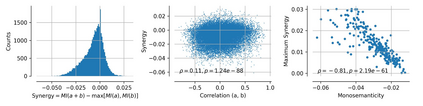
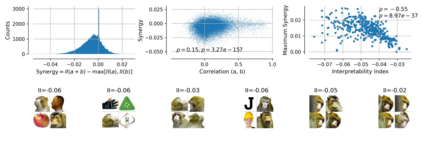
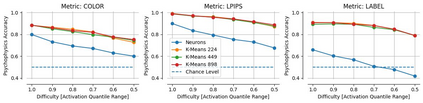
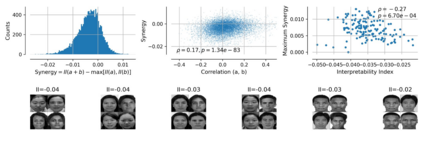
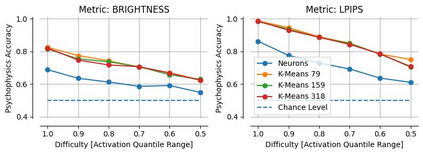
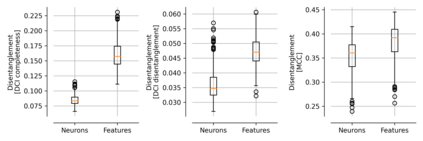
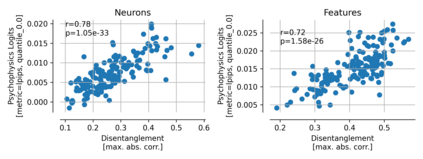
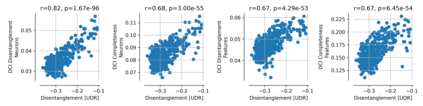
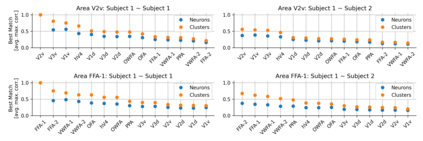
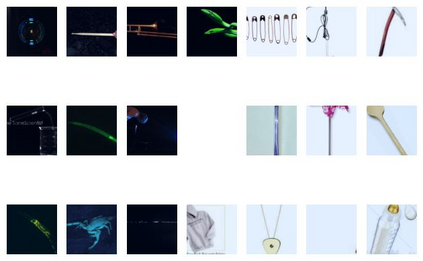
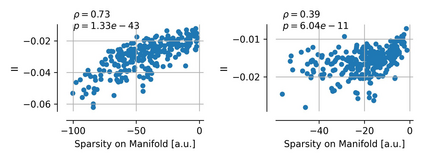
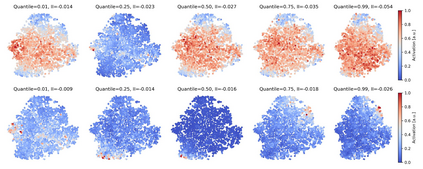
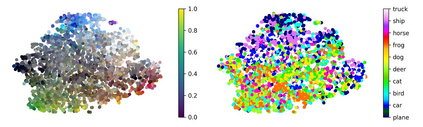
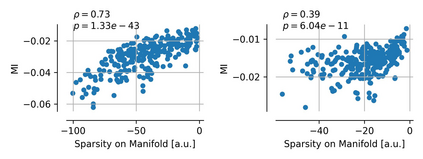
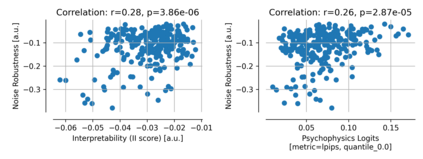
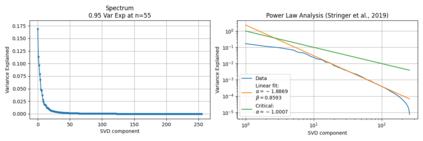
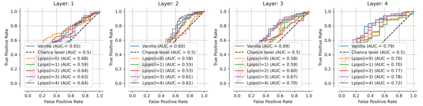
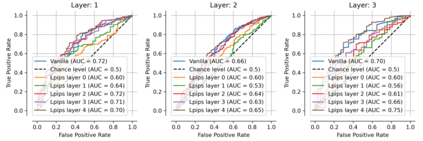
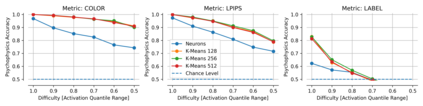
Single neurons in neural networks are often ``interpretable'' in that they represent individual, intuitively meaningful features. However, many neurons exhibit $\textit{mixed selectivity}$, i.e., they represent multiple unrelated features. A recent hypothesis proposes that features in deep networks may be represented in $\textit{superposition}$, i.e., on non-orthogonal axes by multiple neurons, since the number of possible interpretable features in natural data is generally larger than the number of neurons in a given network. Accordingly, we should be able to find meaningful directions in activation space that are not aligned with individual neurons. Here, we propose (1) an automated method for quantifying visual interpretability that is validated against a large database of human psychophysics judgments of neuron interpretability, and (2) an approach for finding meaningful directions in network activation space. We leverage these methods to discover directions in convolutional neural networks that are more intuitively meaningful than individual neurons, as we confirm and investigate in a series of analyses. Moreover, we apply the same method to two recent datasets of visual neural responses in the brain and find that our conclusions largely transfer to real neural data, suggesting that superposition might be deployed by the brain. This also provides a link with disentanglement and raises fundamental questions about robust, efficient and factorized representations in both artificial and biological neural systems.
翻译:暂无翻译