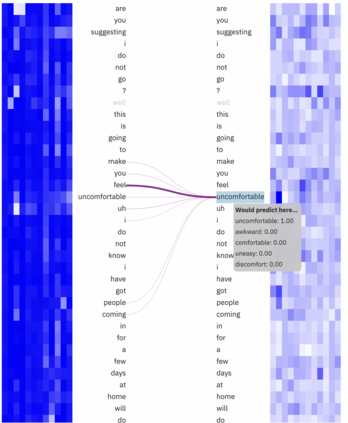
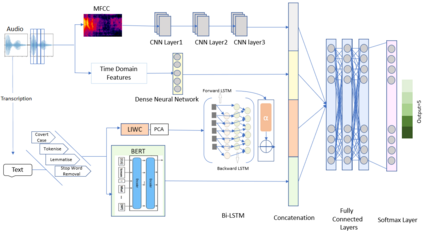
Natural Language Processing has recently made understanding human interaction easier, leading to improved sentimental analysis and behaviour prediction. However, the choice of words and vocal cues in conversations presents an underexplored rich source of natural language data for personal safety and crime prevention. When accompanied by audio analysis, it makes it possible to understand the context of a conversation, including the level of tension or rift between people. Building on existing work, we introduce a new information fusion approach that extracts and fuses multi-level features including verbal, vocal, and text as heterogeneous sources of information to detect the extent of violent behaviours in conversations. Our multilevel multimodel fusion framework integrates four types of information from raw audio signals including embeddings generated from both BERT and Bi-long short-term memory (LSTM) models along with the output of 2D CNN applied to Mel-frequency Cepstrum (MFCC) as well as the output of audio Time-Domain dense layer. The embeddings are then passed to three-layer FC networks, which serve as a concatenated step. Our experimental setup revealed that the combination of the multi-level features from different modalities achieves better performance than using a single one with F1 Score=0.85. We expect that the findings derived from our method provides new approaches for violence detection in conversations.
翻译:自然语言处理最近使人们更容易理解人际互动,从而改进了情感分析和行为预测;然而,在对话中选择言词和发声提示为个人安全和预防犯罪提供了一个探索不足的丰富自然语言数据来源;如果同时进行音频分析,就有可能理解对话的背景,包括人与人之间的紧张或裂痕程度;在现有工作的基础上,我们引入一种新的信息融合方法,提取和结合多层次特征,包括口头、声音和文字,作为不同信息来源,以发现对话中暴力行为的程度;我们多层次的多模范融合框架将来自原始音频信号的四种类型的信息整合在一起,包括由BERT和双长短期记忆(LSTM)模型生成的嵌入信息,以及2DCNN用于Mel-频率 Cepstrum(MCC)的输出以及音频时间-Domain稠密层的输出。然后将嵌入传递到三层FC网络,作为组合步骤。我们的实验性组合显示,从不同模式中生成的多层次特征结合了四种类型的信息,包括由不同方式生成的存储方式生成的F85,我们用一种更好的方法来得出。