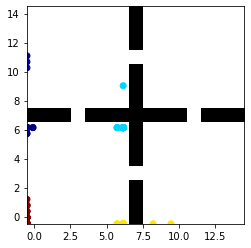
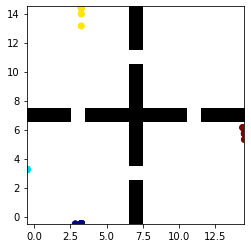
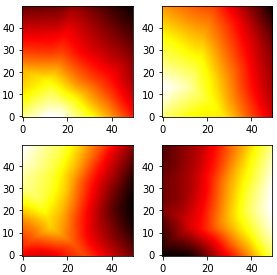
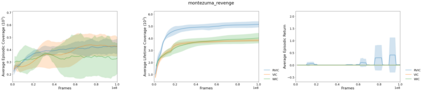
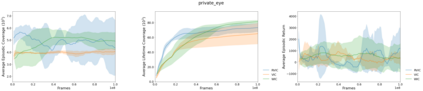
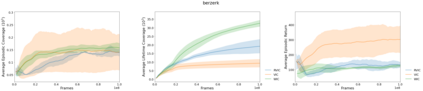
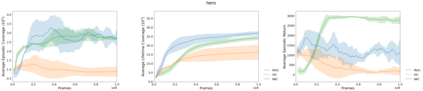
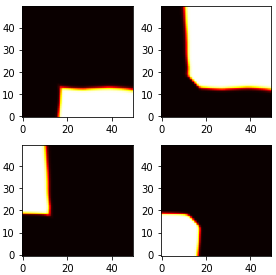This paper deals with the problem of learning a skill-conditioned policy that acts meaningfully in the absence of a reward signal. Mutual information based objectives have shown some success in learning skills that reach a diverse set of states in this setting. These objectives include a KL-divergence term, which is maximized by visiting distinct states even if those states are not far apart in the MDP. This paper presents an approach that rewards the agent for learning skills that maximize the Wasserstein distance of their state visitation from the start state of the skill. It shows that such an objective leads to a policy that covers more distance in the MDP than diversity based objectives, and validates the results on a variety of Atari environments.
翻译:本文论述学习一种技能条件政策的问题,这种政策在没有奖励信号的情况下可以有意义地发挥作用; 以相互信息为基础的目标显示在学习技能方面取得一些成功,这种学习技能能够达到这一背景下的一组不同的国家; 这些目标包括一个KL-divergence 术语,通过访问不同的国家来达到最大化,即使这些国家在多民族民主党中并不相距甚远。 本文介绍了一种方法,奖励学习技能的代理人,使他们从一开始的技能状态开始就最大限度地提高瓦塞斯坦州访问的距离。 它表明,这种目标导致一项政策,涉及多民族民主党的距离,而不是基于多样性的目标,并验证了各种阿塔里环境的结果。