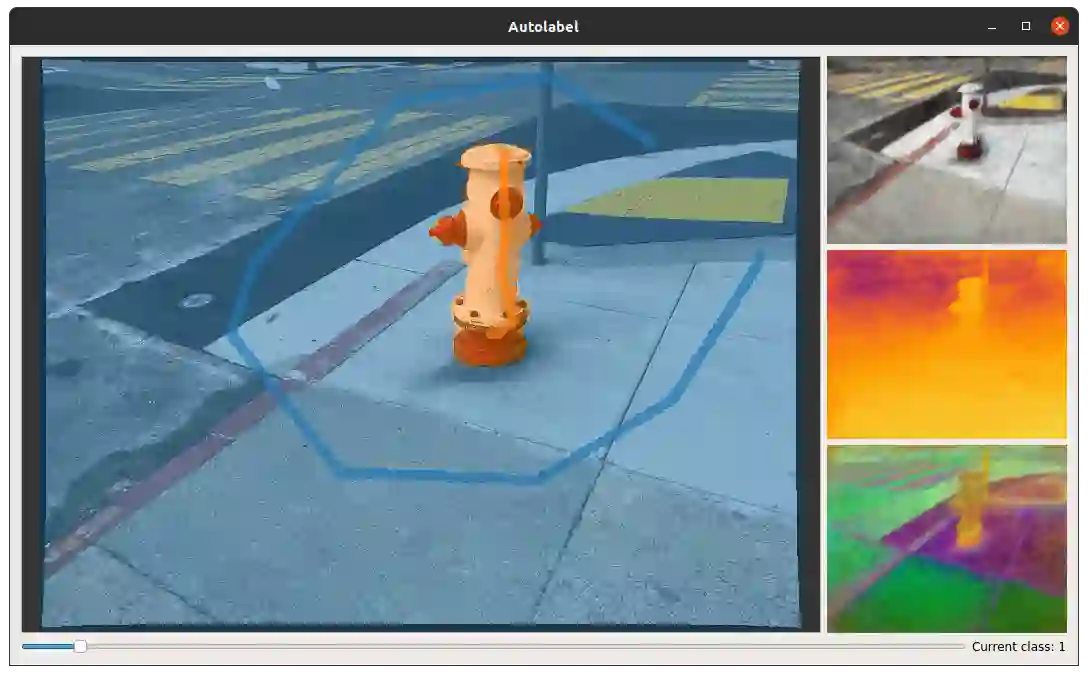
Methods have recently been proposed that densely segment 3D volumes into classes using only color images and expert supervision in the form of sparse semantically annotated pixels. While impressive, these methods still require a relatively large amount of supervision and segmenting an object can take several minutes in practice. Such systems typically only optimize their representation on the particular scene they are fitting, without leveraging any prior information from previously seen images. In this paper, we propose to use features extracted with models trained on large existing datasets to improve segmentation performance. We bake this feature representation into a Neural Radiance Field (NeRF) by volumetrically rendering feature maps and supervising on features extracted from each input image. We show that by baking this representation into the NeRF, we make the subsequent classification task much easier. Our experiments show that our method achieves higher segmentation accuracy with fewer semantic annotations than existing methods over a wide range of scenes.
翻译:最近有人提议,密段三维卷卷将仅仅使用彩色图像和专家监督形式,以稀有的语义说明像素的形式,将高密度三维卷放入各类。虽然这些方法令人印象深刻,但实际上仍然需要相当大量的监督和分割物体需要几分钟时间。这些系统通常只在它们适合的特定场景上优化它们的代表性,而没有利用以前所看到图像的任何先前信息。在本文中,我们提议使用通过在大型现有数据集方面经过培训的模型所提取的特征来改进分解性能。我们通过用体积显示地貌图和对从每个输入图像中提取的特征进行监督,将这种特征的表示制成变成一个神经分野(NERF) 。我们显示,通过将这种表示方式嵌入NERF,我们使随后的分类任务更容易完成。我们的实验表明,我们的方法在广泛的场景中比现有方法的分解性说明要少得多。