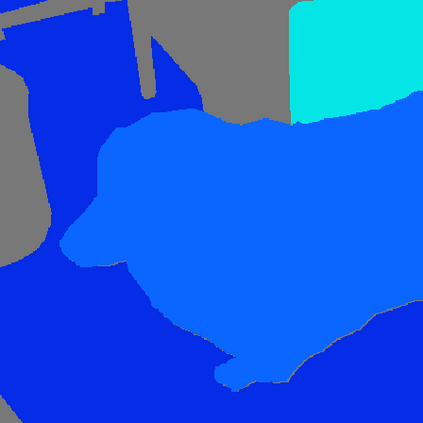
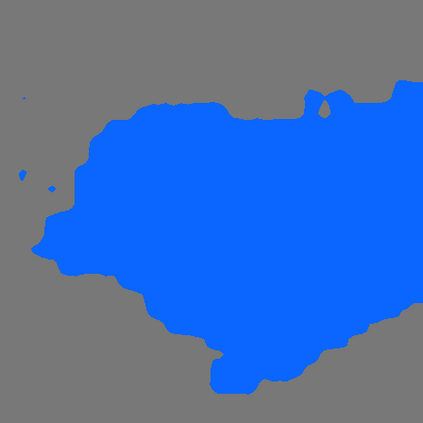
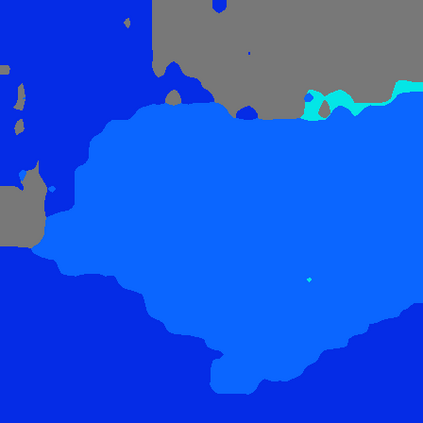
Grouping and recognition are important components of visual scene understanding, e.g., for object detection and semantic segmentation. With end-to-end deep learning systems, grouping of image regions usually happens implicitly via top-down supervision from pixel-level recognition labels. Instead, in this paper, we propose to bring back the grouping mechanism into deep networks, which allows semantic segments to emerge automatically with only text supervision. We propose a hierarchical Grouping Vision Transformer (GroupViT), which goes beyond the regular grid structure representation and learns to group image regions into progressively larger arbitrary-shaped segments. We train GroupViT jointly with a text encoder on a large-scale image-text dataset via contrastive losses. With only text supervision and without any pixel-level annotations, GroupViT learns to group together semantic regions and successfully transfers to the task of semantic segmentation in a zero-shot manner, i.e., without any further fine-tuning. It achieves a zero-shot accuracy of 51.2% mIoU on the PASCAL VOC 2012 and 22.3% mIoU on PASCAL Context datasets, and performs competitively to state-of-the-art transfer-learning methods requiring greater levels of supervision. Project page is available at https://jerryxu.net/GroupViT.
翻译:组合和识别是视觉场景理解的重要组成部分,例如,用于物体探测和语义分解。通过端到端深的学习系统,图像区域的分组通常通过像素级识别标签的自上至下监督而隐含地发生。相反,在本文件中,我们建议将组合机制带回深网络,使语义部分仅通过文本监督自动出现。我们提议了一个等级级组合愿景变异器(GroupViT),它超越常规网格结构代表制,并学习将图像区域分组成逐渐扩大的任意形状部分。我们通过对等损失,用文本编码器联合培训GroupViT,同时在大型图像文本文本-文本数据集中进行编码。只有文本监督,没有像素级的注释,GroupViT学会将语义区域组合起来,并成功地以零发方式将语义分解任务转移给断层,即不做任何进一步的微调。它实现了PASAL VOC/JERU上51.2% mIOU 和22.3% LO-C-C-Crodustrual Instrual Instrual Instrual destrual destrual astrual destruction astructions astrutal lemental lemental lemental lemental routal lections