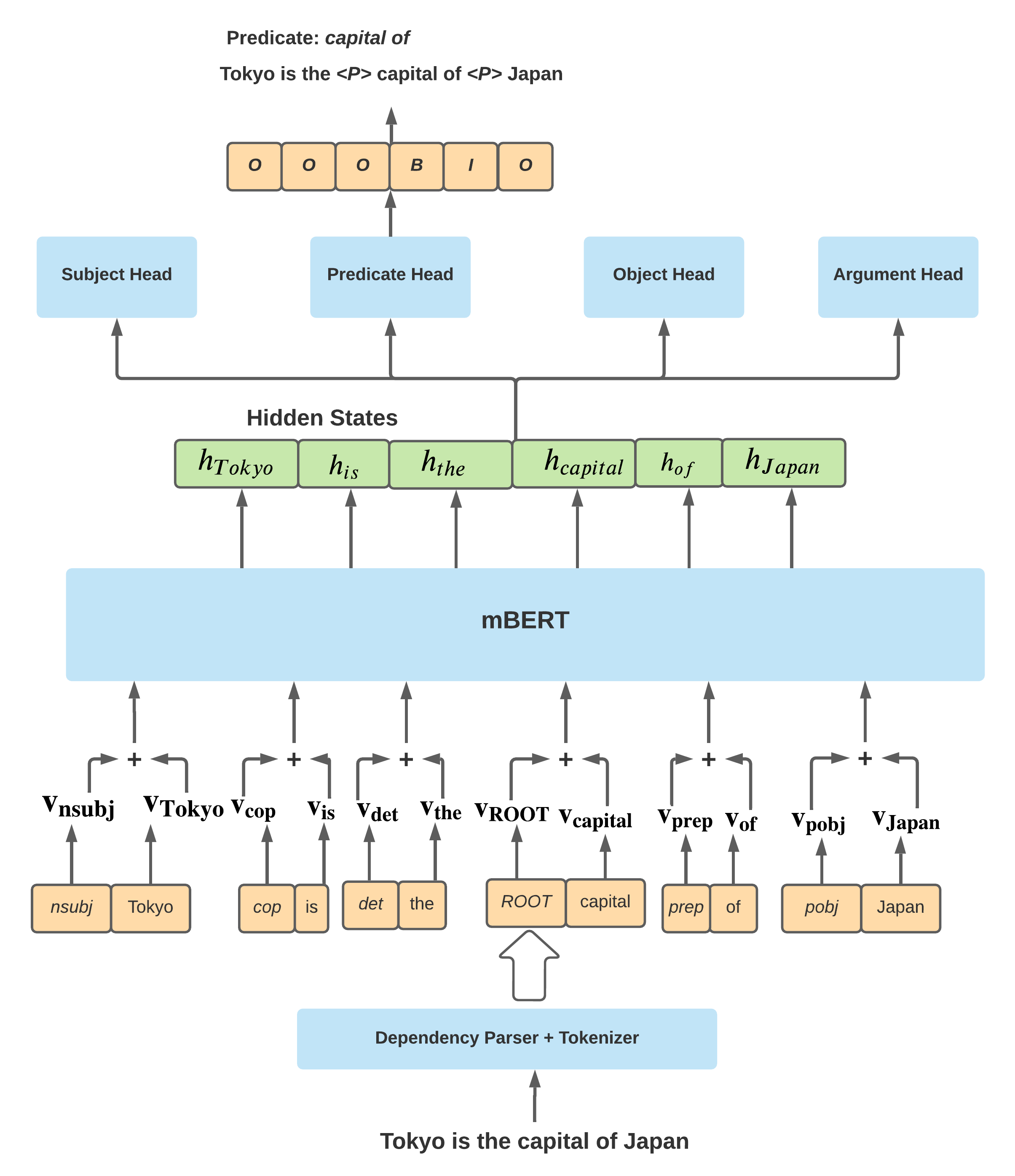
Open Information Extraction (OpenIE) is the task of extracting (subject, predicate, object) triples from natural language sentences. Current OpenIE systems extract all triple slots independently. In contrast, we explore the hypothesis that it may be beneficial to extract triple slots iteratively: first extract easy slots, followed by the difficult ones by conditioning on the easy slots, and therefore achieve a better overall extraction. Based on this hypothesis, we propose a neural OpenIE system, milIE, that operates in an iterative fashion. Due to the iterative nature, the system is also modular -- it is possible to seamlessly integrate rule based extraction systems with a neural end-to-end system, thereby allowing rule based systems to supply extraction slots which milIE can leverage for extracting the remaining slots. We confirm our hypothesis empirically: milIE outperforms SOTA systems on multiple languages ranging from Chinese to Arabic. Additionally, we are the first to provide an OpenIE test dataset for Arabic and Galician.
翻译:开放信息提取( OpenIE) 是从自然语言句中提取( 主题、 上游、 对象) 3 次的任务。 当前 OpenIE 系统独立地提取所有3个空格。 相反, 我们探索了一种假设, 假设它可能有利于迭接地提取3个空格: 首先提取简易的空格, 其次是困难的空格, 然后在轻松的空格上进行调节, 从而实现更好的全面提取 。 基于这个假设, 我们提议一个以迭接方式运行的神经开放信息系统( MIIE ) 。 由于迭接性, 该系统也是模块化的 -- -- 可以无缝地将基于规则的抽取系统与神经端对端系统整合, 从而允许基于规则的系统供应提取空格, MIE 可以利用这些空格来抽取剩余空格。 我们以经验证实了我们的假设: MIIE 将多语言的SOTA系统从中文到阿拉伯文, 。 此外, 我们第一个为阿拉伯语和加利西亚提供 Open 测试数据集 。