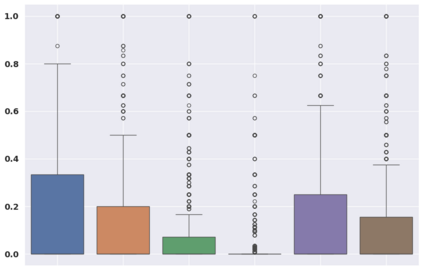
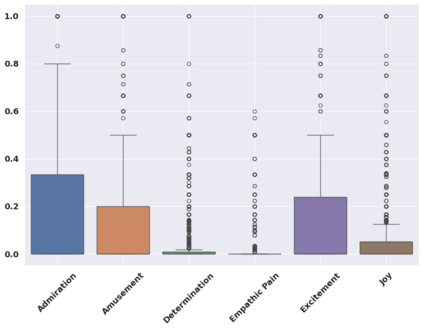
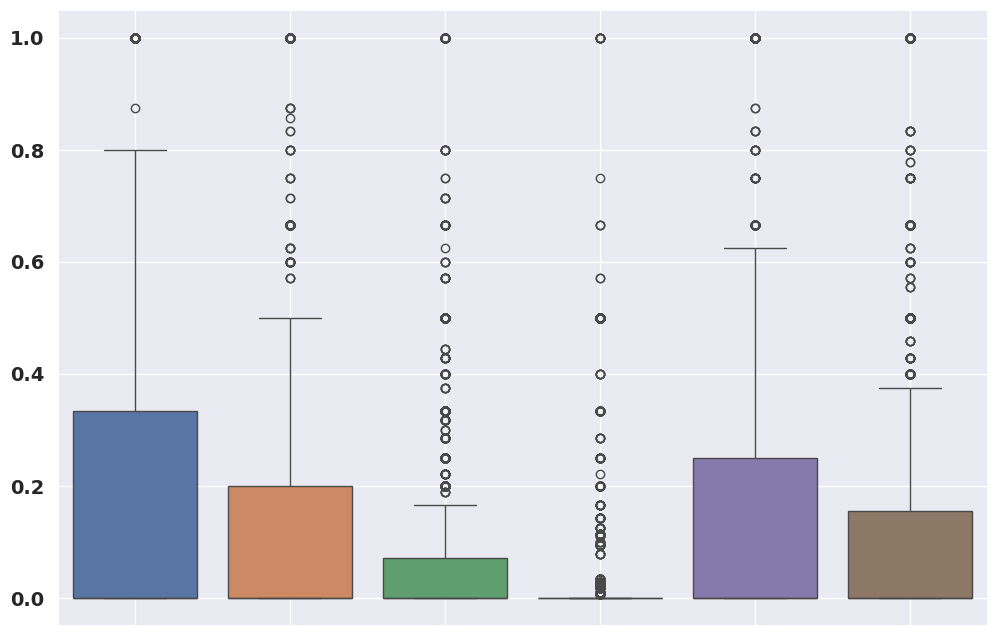
In this study, we propose a methodology for the Emotional Mimicry Intensity (EMI) Estimation task within the context of the 6th Workshop and Competition on Affective Behavior Analysis in-the-wild. Our approach leverages the Wav2Vec 2.0 framework, pre-trained on a comprehensive podcast dataset, to extract a broad range of audio features encompassing both linguistic and paralinguistic elements. We enhance feature representation through a fusion technique that integrates individual features with a global mean vector, introducing global contextual insights into our analysis. Additionally, we incorporate a pre-trained valence-arousal-dominance (VAD) module from the Wav2Vec 2.0 model. Our fusion employs a Long Short-Term Memory (LSTM) architecture for efficient temporal analysis of audio data. Utilizing only the provided audio data, our approach demonstrates significant improvements over the established baseline.
翻译:暂无翻译