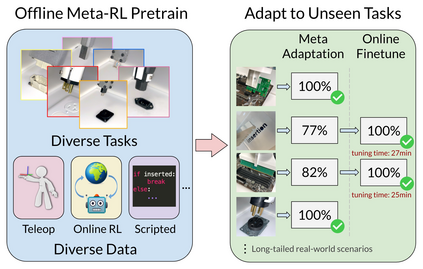
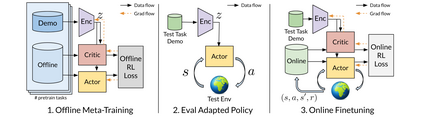
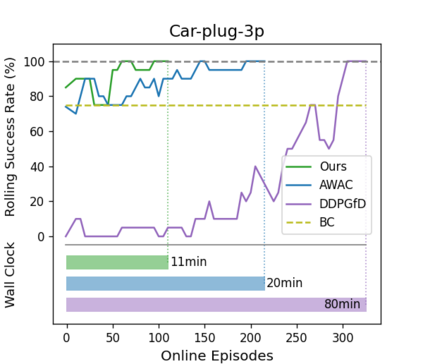
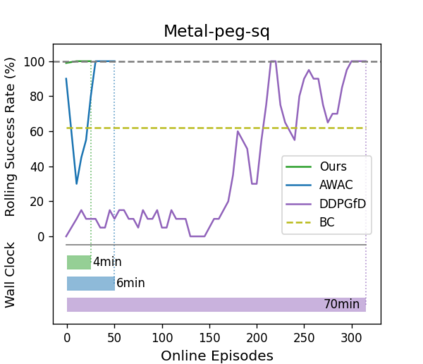
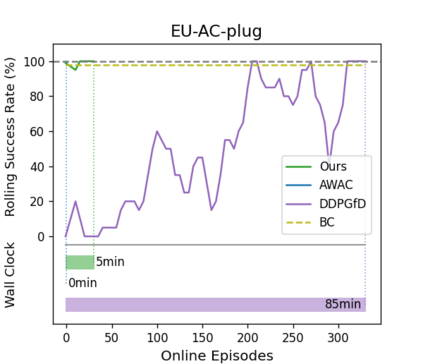
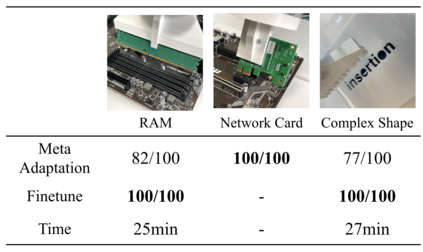
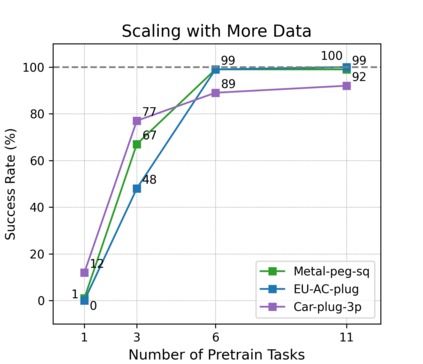
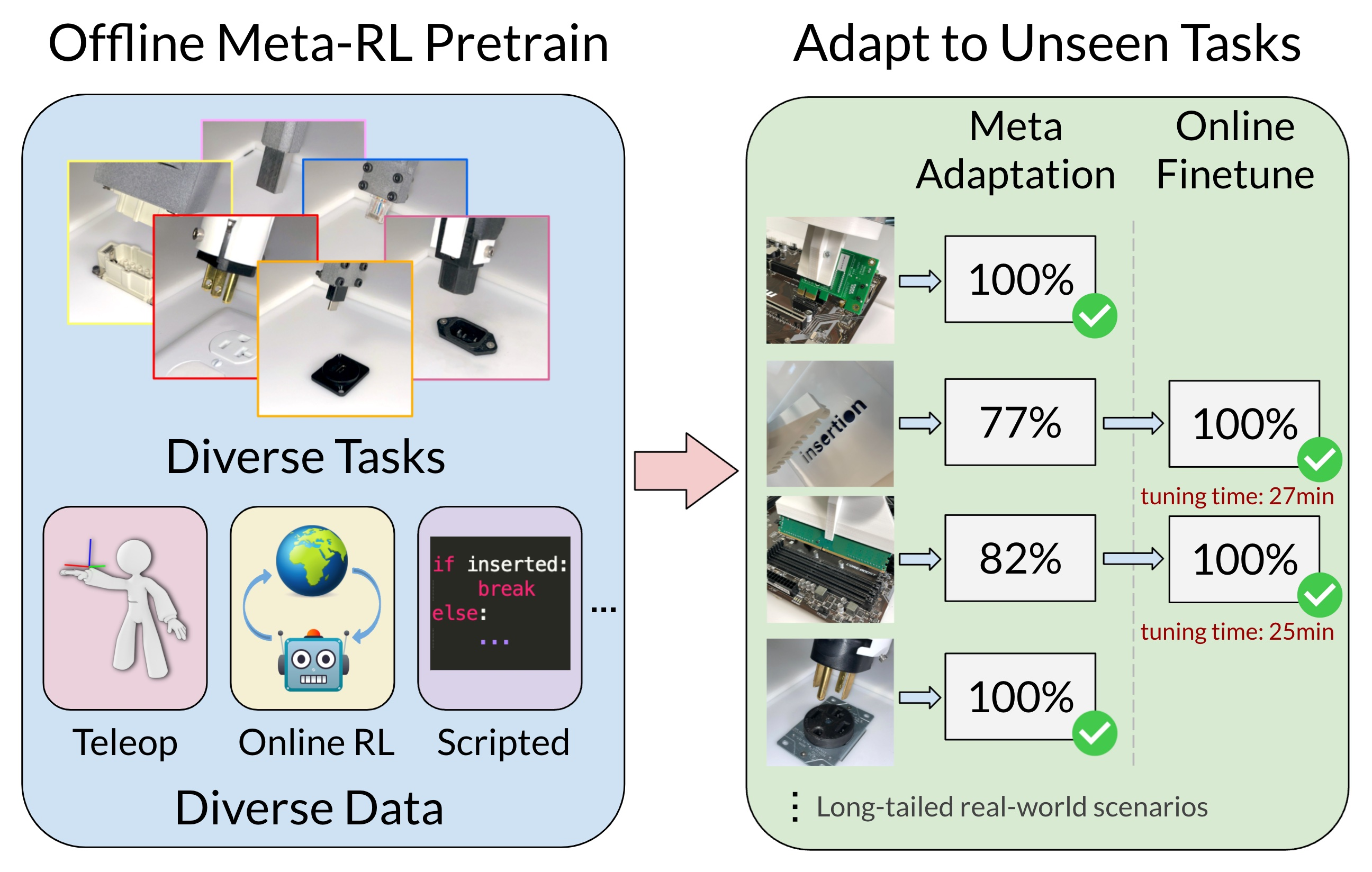
Reinforcement learning (RL) can in principle make it possible for robots to automatically adapt to new tasks, but in practice current RL methods require a very large number of trials to accomplish this. In this paper, we tackle rapid adaptation to new tasks through the framework of meta-learning, which utilizes past tasks to learn to adapt, with a specific focus on industrial insertion tasks. We address two specific challenges by applying meta-learning in this setting. First, conventional meta-RL algorithms require lengthy online meta-training phases. We show that this can be replaced with appropriately chosen offline data, resulting in an offline meta-RL method that only requires demonstrations and trials from each of the prior tasks, without the need to run costly meta-RL procedures online. Second, meta-RL methods can fail to generalize to new tasks that are too different from those seen at meta-training time, which poses a particular challenge in industrial applications, where high success rates are critical. We address this by combining contextual meta-learning with direct online finetuning: if the new task is similar to those seen in the prior data, then the contextual meta-learner adapts immediately, and if it is too different, it gradually adapts through finetuning. We show that our approach is able to quickly adapt to a variety of different insertion tasks, learning how to perform them with a success rate of 100\% using only a fraction of the samples needed for learning the tasks from scratch. Experiment videos and details are available at https://sites.google.com/view/offline-metarl-insertion.
翻译:强化学习( RL) 原则上可以让机器人自动适应新任务, 但实际上, 目前的 RL 方法需要大量测试才能完成。 在本文中, 我们通过元学习框架, 利用过去的任务来适应新任务, 并具体侧重于工业插入任务。 我们通过在这种环境下应用元学习来解决两个具体挑战。 首先, 常规的 MET- RL 算法需要长时间的在线元培训阶段。 我们显示, 可以用适当选择的离线数据来取代这个方法, 从而产生一种离线的 sult- RL 方法, 只需要从先前的每一项任务中演示和试验即可完成。 在本文中, 我们通过元- RL 方法无法概括到新任务, 这些新任务与在元培训期间所看到的任务非常不同, 这给工业应用带来了特殊的挑战, 成功率非常关键。 我们通过将背景的元学习与直接在线微调相结合来解决这个问题: 如果新任务与前数据所看到的任务相似, 只需要每个前一项演示和试验中的每个任务都进行演示和试验, 不需要在线程序上花费昂贵的 Met-learal 。 第二, 方法无法概括地适应新任务是如何在学习, 我们的升级到可以很快地学习一个不同。 。