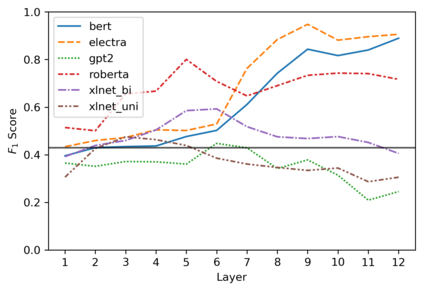
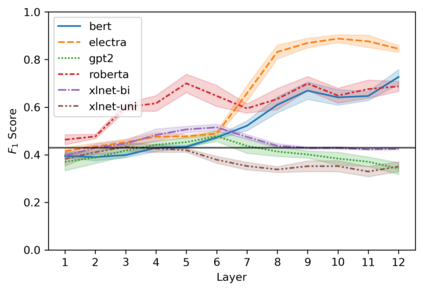
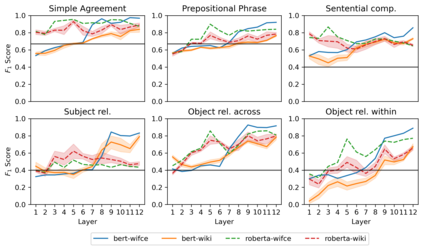
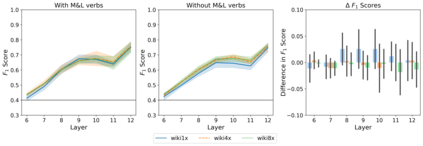
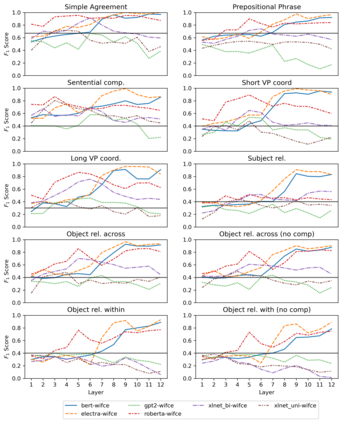
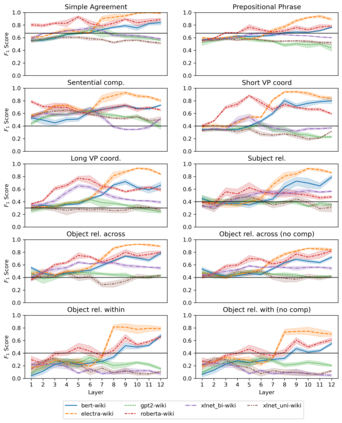
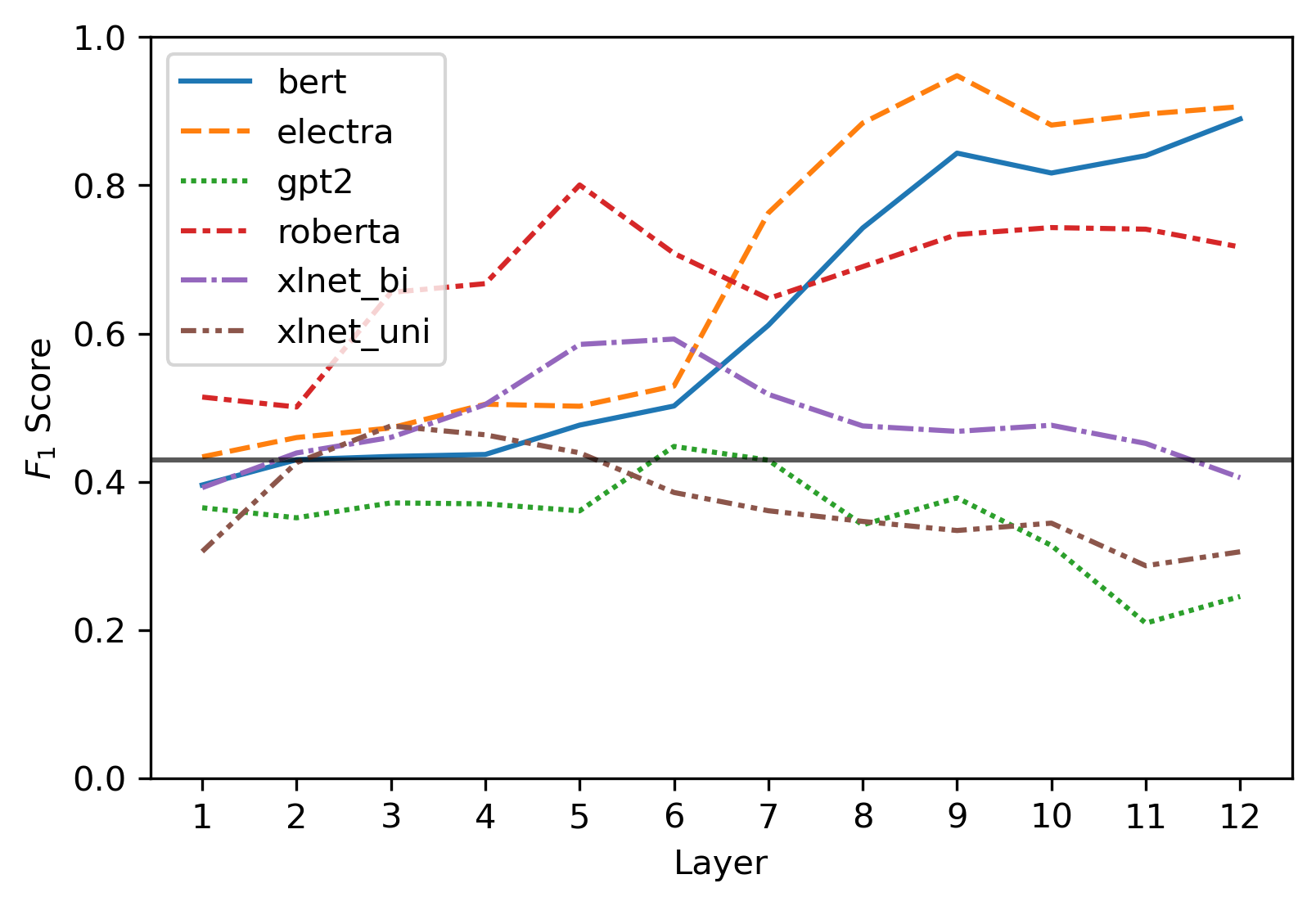
Targeted studies testing knowledge of subject-verb agreement (SVA) indicate that pre-trained language models encode syntactic information. We assert that if models robustly encode subject-verb agreement, they should be able to identify when agreement is correct and when it is incorrect. To that end, we propose grammatical error detection as a diagnostic probe to evaluate token-level contextual representations for their knowledge of SVA. We evaluate contextual representations at each layer from five pre-trained English language models: BERT, XLNet, GPT-2, RoBERTa, and ELECTRA. We leverage public annotated training data from both English second language learners and Wikipedia edits, and report results on manually crafted stimuli for subject-verb agreement. We find that masked language models linearly encode information relevant to the detection of SVA errors, while the autoregressive models perform on par with our baseline. However, we also observe a divergence in performance when probes are trained on different training sets, and when they are evaluated on different syntactic constructions, suggesting the information pertaining to SVA error detection is not robustly encoded.
翻译:我们主张,如果模型对主题动词协议进行严格编码,它们应该能够确定协议何时正确,何时不正确。为此,我们提议将语法错误检测作为诊断性检测器,以评价其了解SVA的象征性背景表现;我们从五个经过预先训练的英语模型(BERT、XLNet、GPT-2、RoBERTA和ELECTRA)中评估每个层次的背景表现。我们利用英文第二语言学习者和维基百科编辑的附加说明的培训数据,并报告手动制作的模拟数据,供主题动动词协议使用。我们发现,蒙面语言模型将SVA错误的检测相关信息线性编码,而自反模式与我们的基线相当。但是,我们还注意到,在对不同培训组进行测试时,以及在对不同的合成结构进行评估时,在对SVA错误的检测信息进行严格编码时,表现也存在差异。