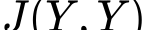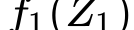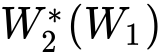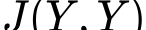The calibration and training of a neural network is a complex and time-consuming procedure that requires significant computational resources to achieve satisfactory results. Key obstacles are a large number of hyperparameters to select and the onset of overfitting in the face of a small amount of data. In this framework, we propose an innovative training strategy for feed-forward architectures - called split-boost - that improves performance and automatically includes a regularizing behaviour without modeling it explicitly. Such a novel approach ultimately allows us to avoid explicitly modeling the regularization term, decreasing the total number of hyperparameters and speeding up the tuning phase. The proposed strategy is tested on a real-world (anonymized) dataset within a benchmark medical insurance design problem.
翻译:暂无翻译