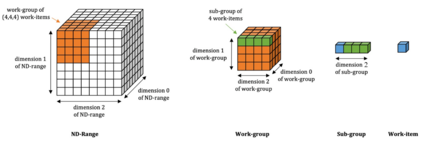
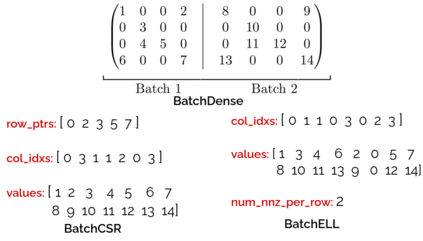
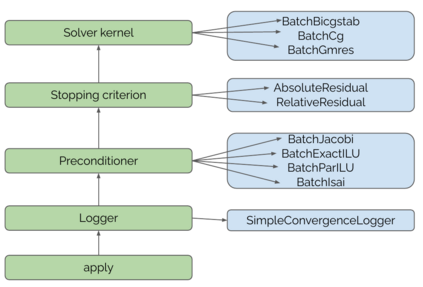
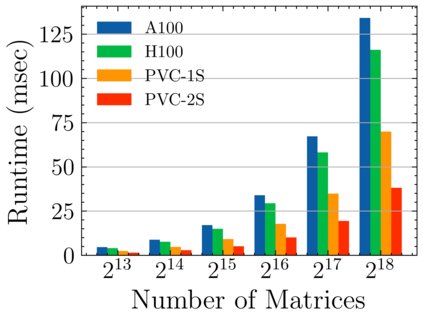
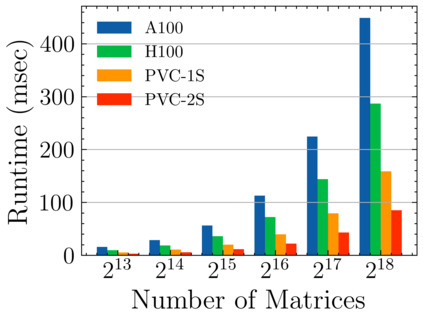
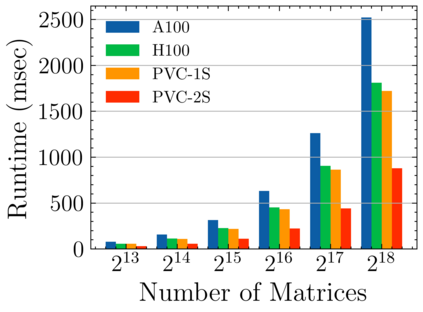
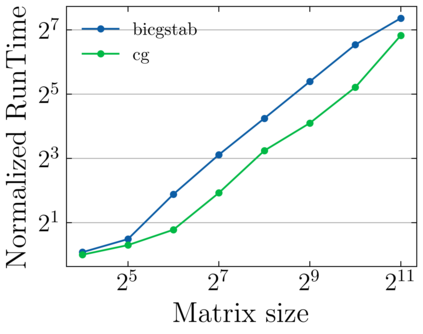
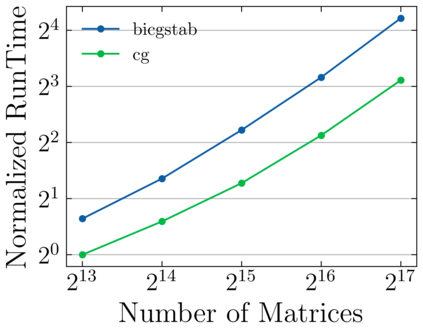
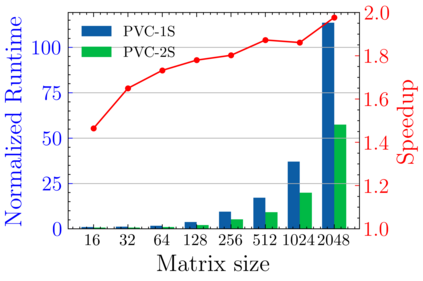
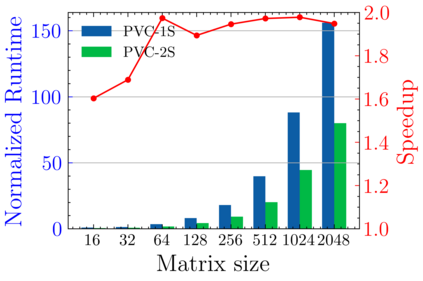
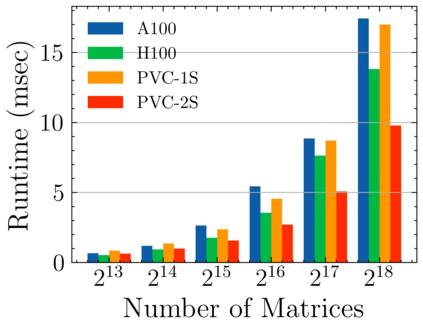
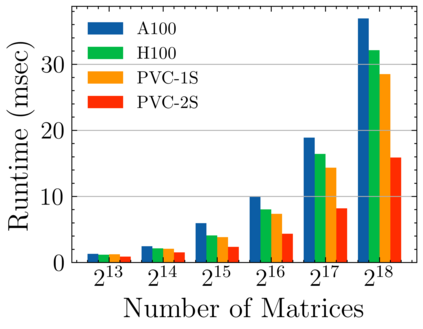
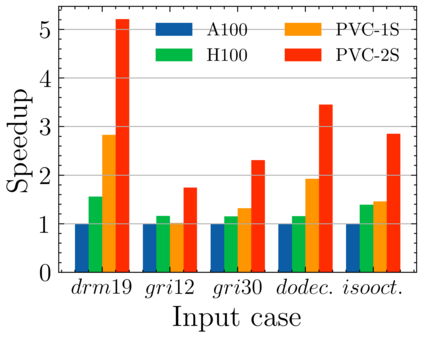
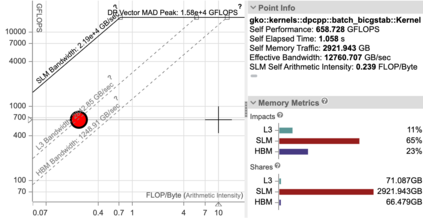
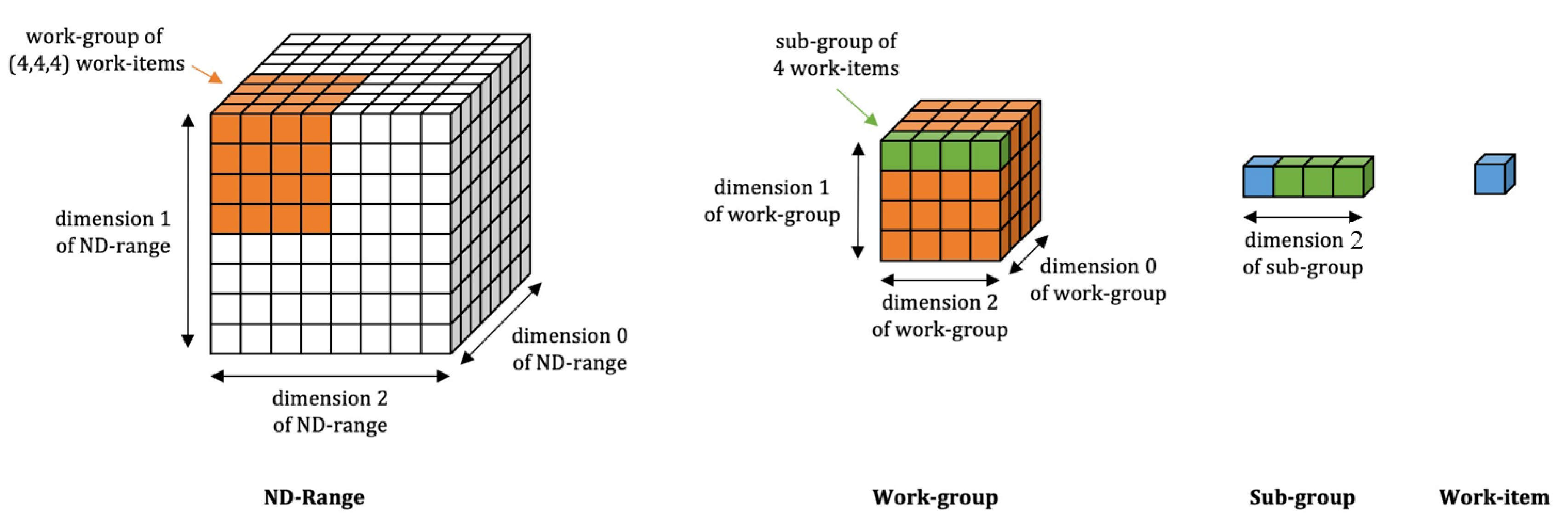
Batched linear solvers play a vital role in computational sciences, especially in the fields of plasma physics and combustion simulations. With the imminent deployment of the Aurora Supercomputer and other upcoming systems equipped with Intel GPUs, there is a compelling demand to expand the capabilities of these solvers for Intel GPU architectures. In this paper, we present our efforts in porting and optimizing the batched iterative solvers on Intel GPUs using the SYCL programming model. The SYCL-based implementation exhibits impressive performance and scalability on the Intel GPU Max 1550s (Ponte Vecchio GPUs). The solvers outperform our previous CUDA implementation on NVIDIA H100 GPUs by an average of 2.4x for the PeleLM application inputs. The batched solvers are ready for production use in real-world scientific applications through the Ginkgo library.
翻译:暂无翻译