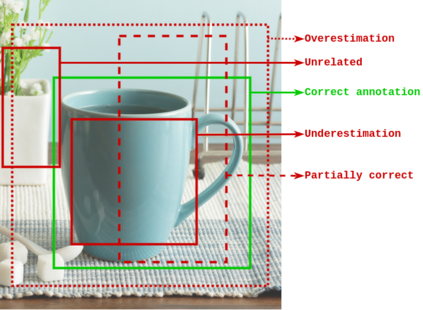
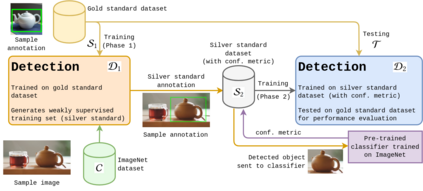
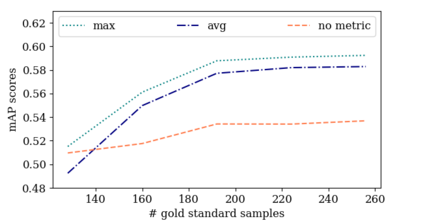
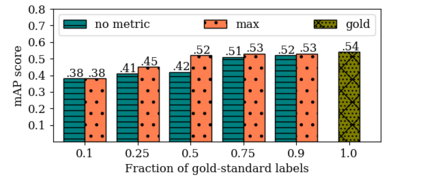
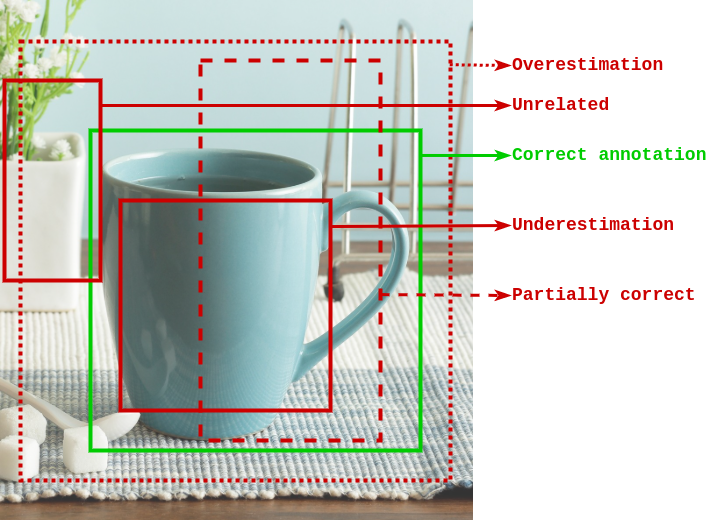
Obtaining gold standard annotated data for object detection is often costly, involving human-level effort. Semi-supervised object detection algorithms solve the problem with a small amount of gold-standard labels and a large unlabelled dataset used to generate silver-standard labels. But training on the silver standard labels does not produce good results, because they are machine-generated annotations. In this work, we design a modified loss function to train on large silver standard annotated sets generated by a weak annotator. We include a confidence metric associated with the annotation as an additional term in the loss function, signifying the quality of the annotation. We test the effectiveness of our approach on various test sets and use numerous variations to compare the results with some of the current approaches to object detection. In comparison with the baseline where no confidence metric is used, we achieved a 4\% gain in mAP with 25\% labeled data and 10\% gain in mAP with 50\% labeled data by using the proposed confidence metric.
翻译:为探测物体而获取黄金标准附加说明数据往往费用高昂,需要人的努力。半受监督的物体探测算法用少量金标准标签和用于生成银标准标签的大型无标签数据集解决问题。但是,银标准标签培训不会产生好结果,因为它们是机器生成的注释。在这项工作中,我们设计了经修改的损失函数,用一个弱小的标注员产生的大型银标准附加说明数据集进行培训。我们在损失函数中添加了一个与注释相关的信任度量度值,作为附加的术语,表示说明说明质量。我们测试了我们各种测试数据集的方法的有效性,并使用许多变异方法将结果与目前一些检验目标的方法进行比较。与没有使用信任度基准的基线相比,我们通过使用拟议的信任度度指标,在MAP中取得了4 ⁇ 收益,我们用25 ⁇ 标签数据实现了4 ⁇,在50 ⁇ 标记数据的 mAP中取得了10 ⁇ 收益。