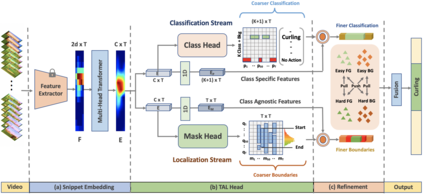
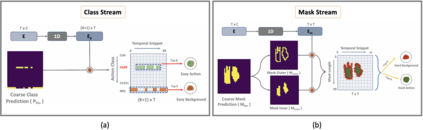
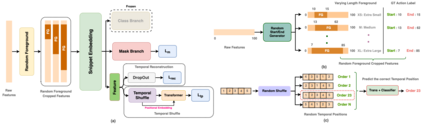
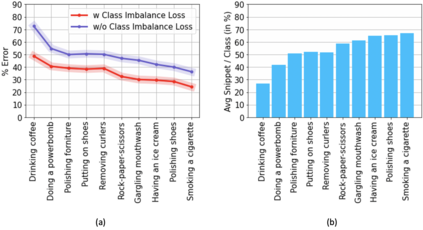
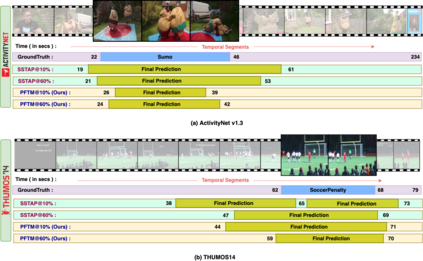
Existing temporal action detection (TAD) methods rely on a large number of training data with segment-level annotations. Collecting and annotating such a training set is thus highly expensive and unscalable. Semi-supervised TAD (SS-TAD) alleviates this problem by leveraging unlabeled videos freely available at scale. However, SS-TAD is also a much more challenging problem than supervised TAD, and consequently much under-studied. Prior SS-TAD methods directly combine an existing proposal-based TAD method and a SSL method. Due to their sequential localization (e.g, proposal generation) and classification design, they are prone to proposal error propagation. To overcome this limitation, in this work we propose a novel Semi-supervised Temporal action detection model based on PropOsal-free Temporal mask (SPOT) with a parallel localization (mask generation) and classification architecture. Such a novel design effectively eliminates the dependence between localization and classification by cutting off the route for error propagation in-between. We further introduce an interaction mechanism between classification and localization for prediction refinement, and a new pretext task for self-supervised model pre-training. Extensive experiments on two standard benchmarks show that our SPOT outperforms state-of-the-art alternatives, often by a large margin. The PyTorch implementation of SPOT is available at https://github.com/sauradip/SPOT
翻译:现有的时间行动探测方法(TAD)取决于大量具有分层说明的培训数据。因此,收集和批注这样的培训组非常昂贵,而且无法推广。半监督的TAD(SS-TAD)通过利用无标签的免费免费视频缓解了这一问题。然而,SS-TAD(SPOT)也比受监督的TAD(MASD)和分类结构更具有挑战性。先前的SS-TAD方法直接结合了基于建议的现有TAD方法和SSL方法。由于它们相继的本地化(例如,建议生成)和分类设计,它们容易出现建议错误传播。为了克服这一限制,我们在此工作中提出了一个新的半监督的TADAD(SS-TAD)行动探测模型,该模型与受监督的TADAD(mask生成)和分类结构并行(因此研究不足)。这种新型设计通过切断错误传播途径,有效地消除了本地化和分类与分类之间的依赖性。我们进一步引入了用于预测的本地化和本地化(ProOT/SP)边际比值改进的新的替代机制机制。在大规模实验上展示了我们现有的POTART的大规模实验标准基准。