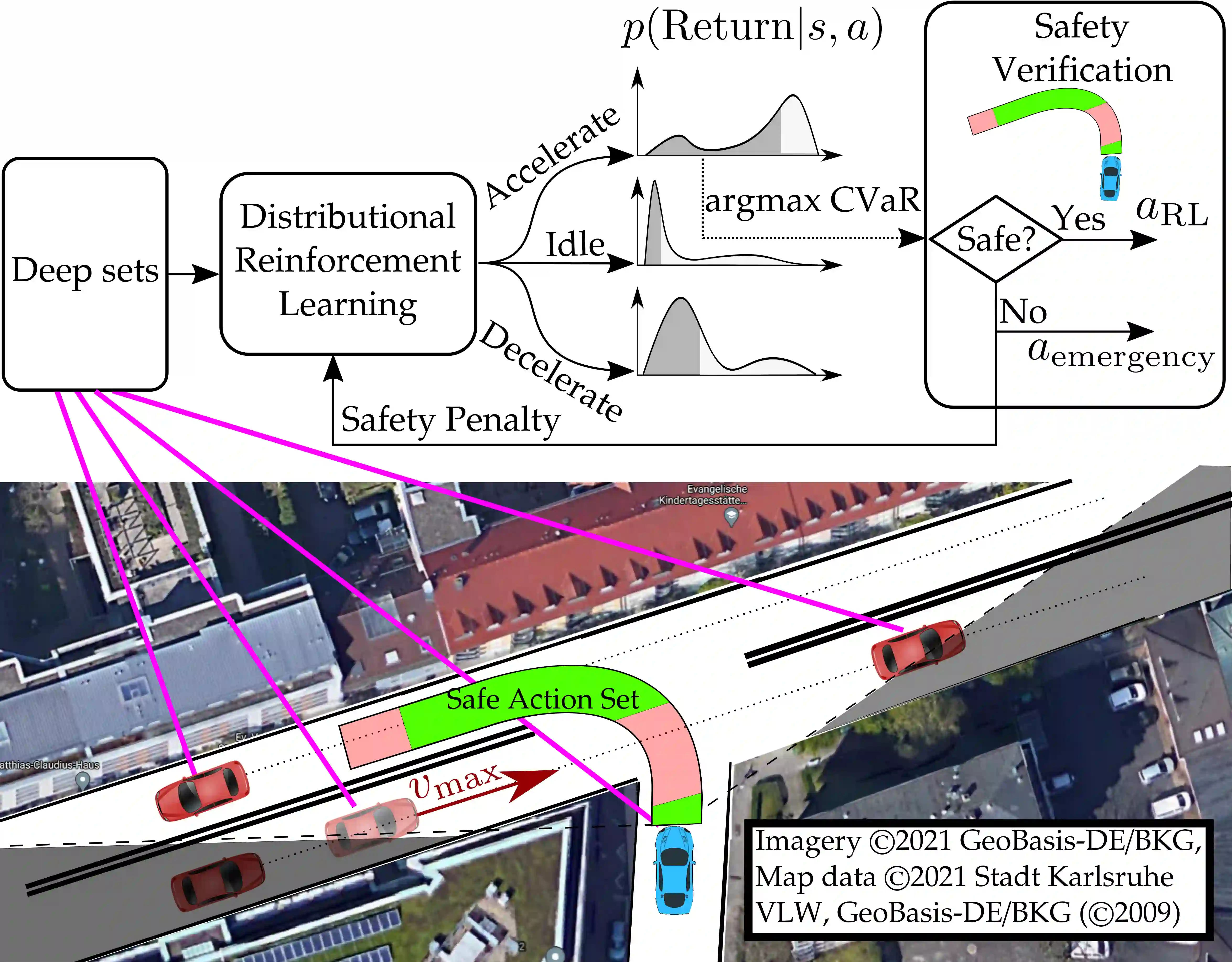
Despite recent advances in reinforcement learning (RL), its application in safety critical domains like autonomous vehicles is still challenging. Although punishing RL agents for risky situations can help to learn safe policies, it may also lead to highly conservative behavior. In this paper, we propose a distributional RL framework in order to learn adaptive policies that can tune their level of conservativity at run-time based on the desired comfort and utility. Using a proactive safety verification approach, the proposed framework can guarantee that actions generated from RL are fail-safe according to the worst-case assumptions. Concurrently, the policy is encouraged to minimize safety interference and generate more comfortable behavior. We trained and evaluated the proposed approach and baseline policies using a high level simulator with a variety of randomized scenarios including several corner cases which rarely happen in reality but are very crucial. In light of our experiments, the behavior of policies learned using distributional RL can be adaptive at run-time and robust to the environment uncertainty. Quantitatively, the learned distributional RL agent drives in average 8 seconds faster than the normal DQN policy and requires 83\% less safety interference compared to the rule-based policy with slightly increasing the average crossing time. We also study sensitivity of the learned policy in environments with higher perception noise and show that our algorithm learns policies that can still drive reliable when the perception noise is two times higher than the training configuration for automated merging and crossing at occluded intersections.
翻译:尽管在强化学习(RL)方面最近有所进展,但在诸如自治车辆等安全关键领域应用该标准仍然具有挑战性。虽然针对危险情况惩罚RL代理商可有助于学习安全政策,但也可能导致高度保守的行为。在本文件中,我们提议了一个分配RL框架,以便学习适应性政策,这种政策能够根据所期望的舒适和实用性在运行时调整其保守程度。采用积极主动的安全核查方法,拟议框架可以保证根据最坏假设,RL产生的行动是安全的。与此同时,鼓励该政策尽量减少安全干扰,并产生更舒适的行为。我们用高水平的模拟器,对拟议方法和基线政策进行了培训和评估,这些模拟器具有各种随机化的情景,包括一些在现实中很少发生但非常关键的转角案例。根据我们的实验,使用分配RL的政策行为可以在运行时适应性强力地适应环境的不确定性。在正常的DQN政策之前平均8秒钟里,所学的分发RL代理商驱动力比正常的DQN政策更快,在基于规则的政策中要求比较高的安全干扰程度低83 ⁇,而在以略的高度的跨边界政策中,同时,我们所学到的标准化政策学会的标准化政策中,在学习的标准化政策中学习到的高度的高度的高度的高度的动态学。