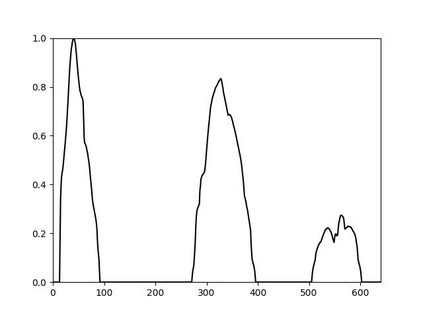
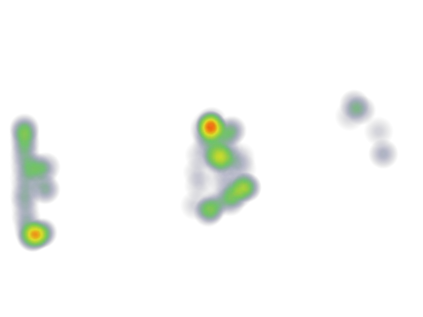
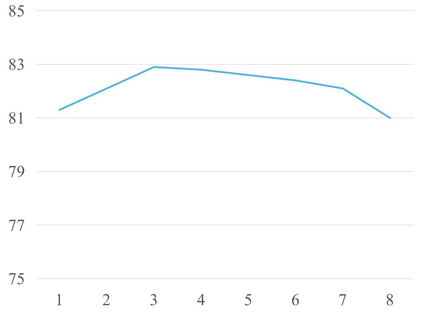
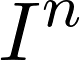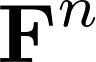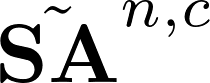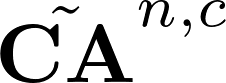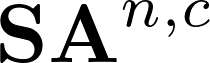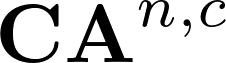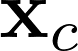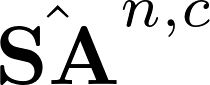Recently many multi-label image recognition (MLR) works have made significant progress by introducing pre-trained object detection models to generate lots of proposals or utilizing statistical label co-occurrence enhance the correlation among different categories. However, these works have some limitations: (1) the effectiveness of the network significantly depends on pre-trained object detection models that bring expensive and unaffordable computation; (2) the network performance degrades when there exist occasional co-occurrence objects in images, especially for the rare categories. To address these problems, we propose a novel and effective semantic representation and dependency learning (SRDL) framework to learn category-specific semantic representation for each category and capture semantic dependency among all categories. Specifically, we design a category-specific attentional regions (CAR) module to generate channel/spatial-wise attention matrices to guide model to focus on semantic-aware regions. We also design an object erasing (OE) module to implicitly learn semantic dependency among categories by erasing semantic-aware regions to regularize the network training. Extensive experiments and comparisons on two popular MLR benchmark datasets (i.e., MS-COCO and Pascal VOC 2007) demonstrate the effectiveness of the proposed framework over current state-of-the-art algorithms.
翻译:最近,许多多标签图像识别(MLR)工程取得了显著进展,引进了经过预先培训的物体检测模型,以产生大量建议或使用统计标签共同发现,从而提高了不同类别之间的关联性;然而,这些工程有一些局限性:(1) 网络的有效性在很大程度上取决于经过培训的物体检测模型,这些模型带来昂贵和负担不起的计算;(2) 当图像中偶尔出现共同对象时,网络性能会下降,特别是稀有类别时,网络性能会下降。为解决这些问题,我们提议了一个新颖和有效的语义代表性和依赖性学习框架(SRDL),以学习每个类别的具体类别语义代表性,并捕捉到所有类别之间的语义依赖性。具体地说,我们设计了一个针对特定类别的注意区域模块,以生成频道/空间关注模型,以指导模型侧重于语义-认知区域,特别是稀有类别。我们还设计了一个对象删除模块,以隐含地学习各类别之间的语义依赖性。我们提议通过消除语义-认知区域来规范网络培训。CO对两种流行的MLR基准数据框架进行广泛的实验和比较。2007年版本-MS-salacal-vical-vicalation框架(i,MS-sal-st-st-st)