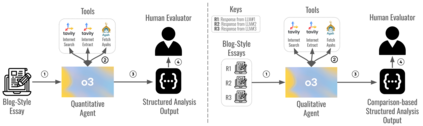
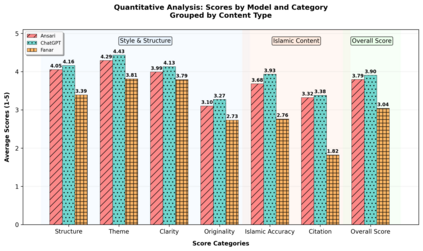
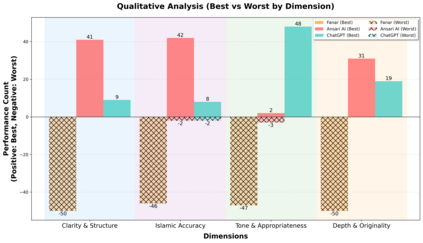
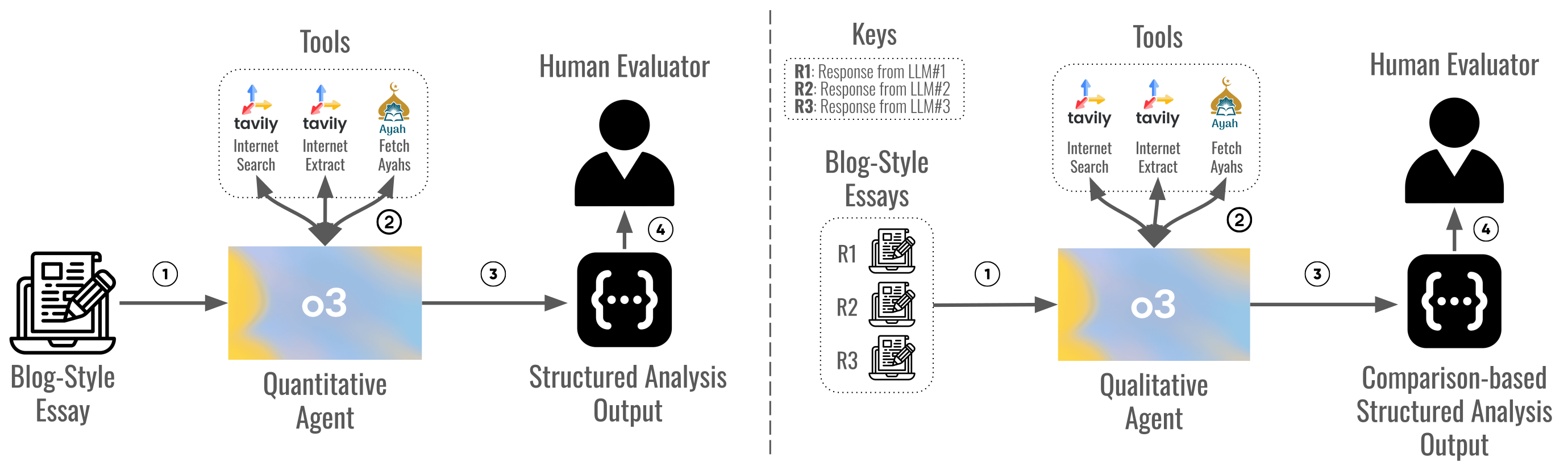
Large language models are increasingly used for Islamic guidance, but risk misquoting texts, misapplying jurisprudence, or producing culturally inconsistent responses. We pilot an evaluation of GPT-4o, Ansari AI, and Fanar on prompts from authentic Islamic blogs. Our dual-agent framework uses a quantitative agent for citation verification and six-dimensional scoring (e.g., Structure, Islamic Consistency, Citations) and a qualitative agent for five-dimensional side-by-side comparison (e.g., Tone, Depth, Originality). GPT-4o scored highest in Islamic Accuracy (3.93) and Citation (3.38), Ansari AI followed (3.68, 3.32), and Fanar lagged (2.76, 1.82). Despite relatively strong performance, models still fall short in reliably producing accurate Islamic content and citations -- a paramount requirement in faith-sensitive writing. GPT-4o had the highest mean quantitative score (3.90/5), while Ansari AI led qualitative pairwise wins (116/200). Fanar, though trailing, introduces innovations for Islamic and Arabic contexts. This study underscores the need for community-driven benchmarks centering Muslim perspectives, offering an early step toward more reliable AI in Islamic knowledge and other high-stakes domains such as medicine, law, and journalism.
翻译:暂无翻译