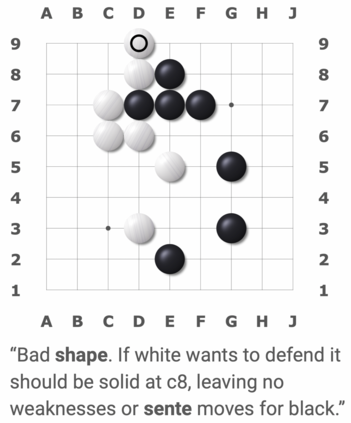
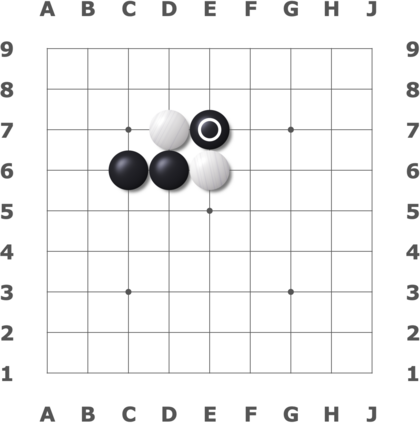
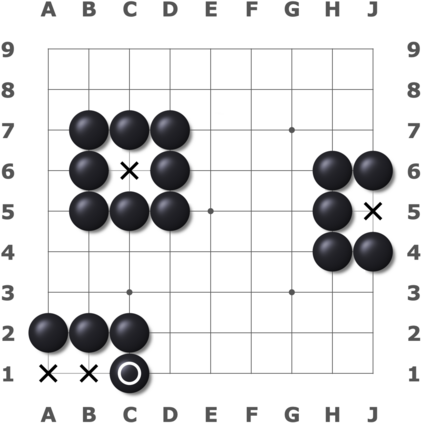
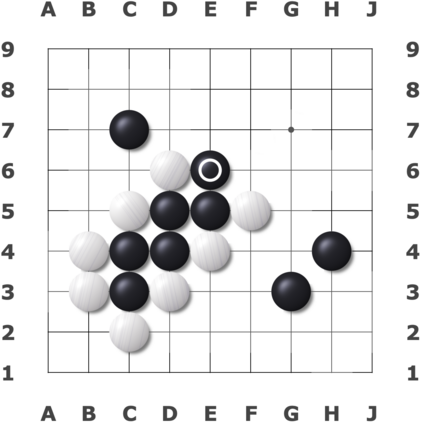
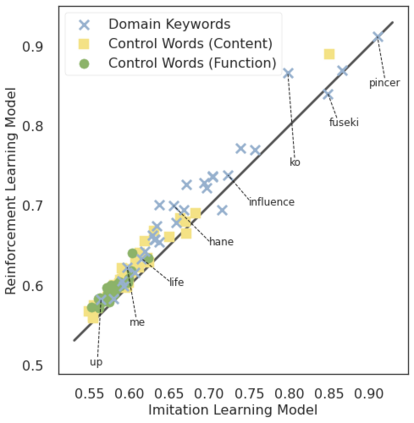
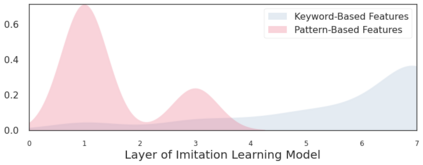
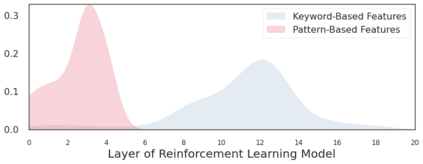
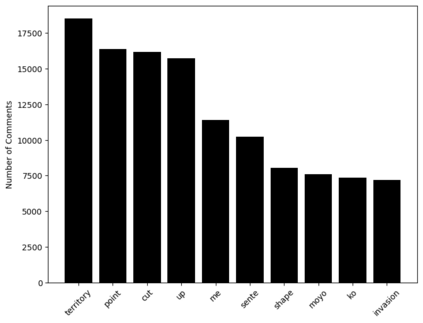
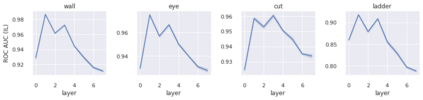
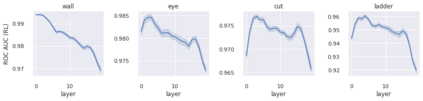
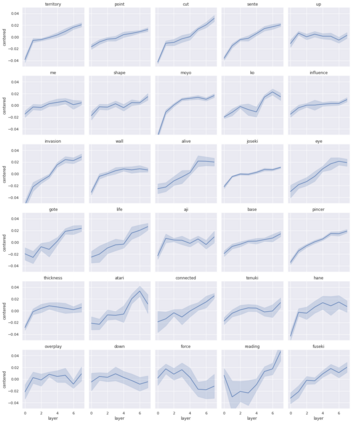
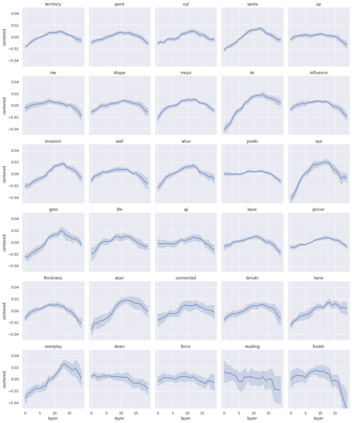
We present a new dataset containing 10K human-annotated games of Go and show how these natural language annotations can be used as a tool for model interpretability. Given a board state and its associated comment, our approach uses linear probing to predict mentions of domain-specific terms (e.g., ko, atari) from the intermediate state representations of game-playing agents like AlphaGo Zero. We find these game concepts are nontrivially encoded in two distinct policy networks, one trained via imitation learning and another trained via reinforcement learning. Furthermore, mentions of domain-specific terms are most easily predicted from the later layers of both models, suggesting that these policy networks encode high-level abstractions similar to those used in the natural language annotations.
翻译:我们提出了一个包含10K人注解游戏的新数据集,并展示如何将这些自然语言说明用作模型解释的工具。 鉴于一个董事会及其相关评论,我们的方法使用线性调查来预测从像阿尔法戈零号这样的游戏玩家中间状态中显示的域名(如ko, atari)的引用。我们发现这些游戏概念没有在两个不同的政策网络中进行细微的编码,一个通过模仿学习培训,另一个通过强化学习培训。 此外,提及特定域名最容易从两个模型的后层预测,表明这些政策网络包含与自然语言说明中所使用的高层次抽象内容类似的高层次抽象内容。