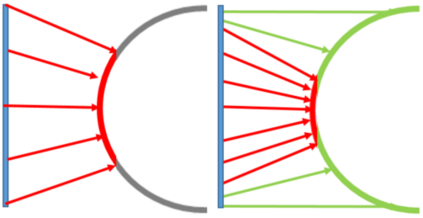
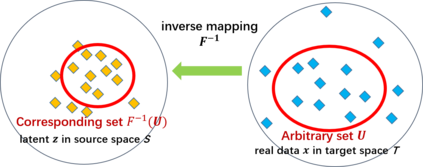
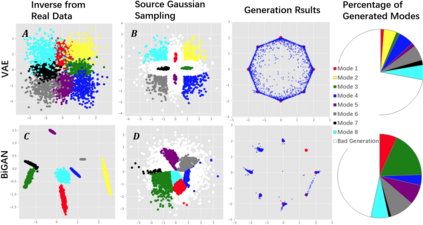
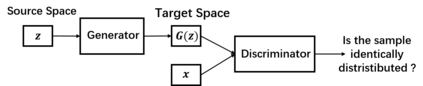
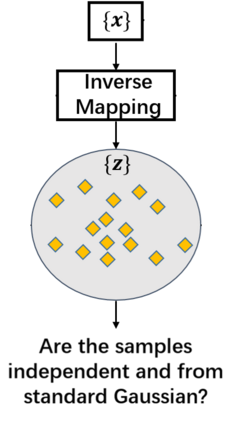
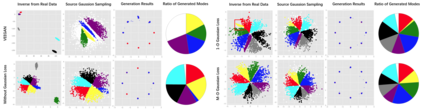
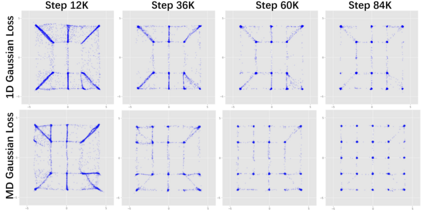
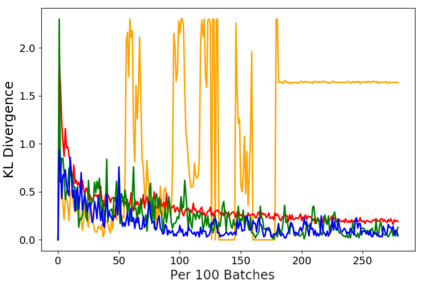
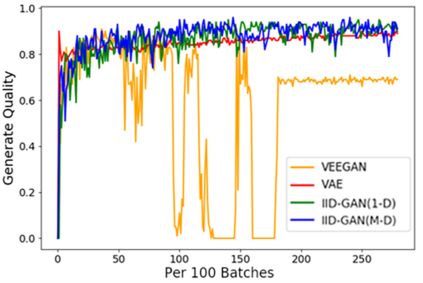
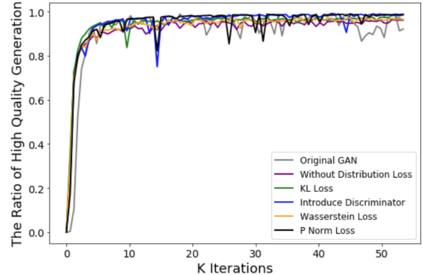
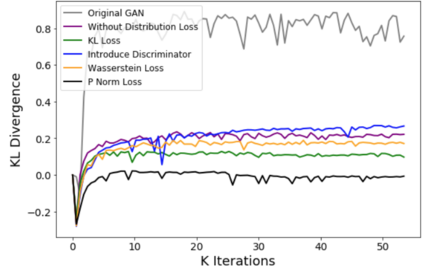
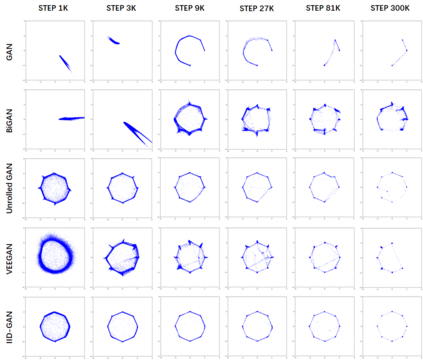
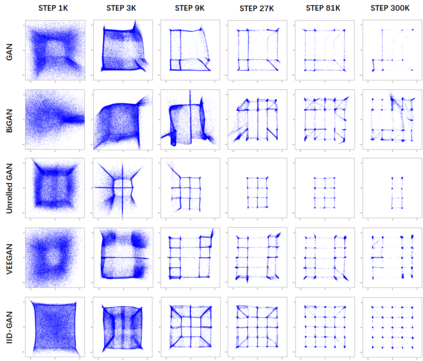
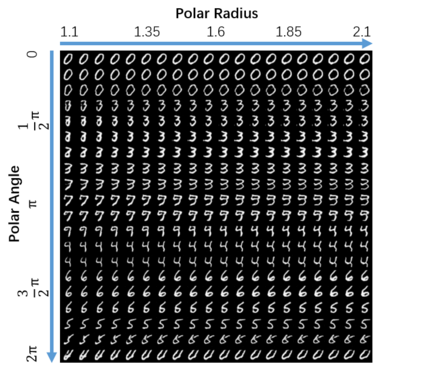
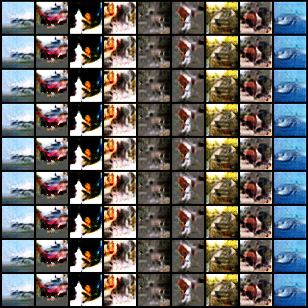
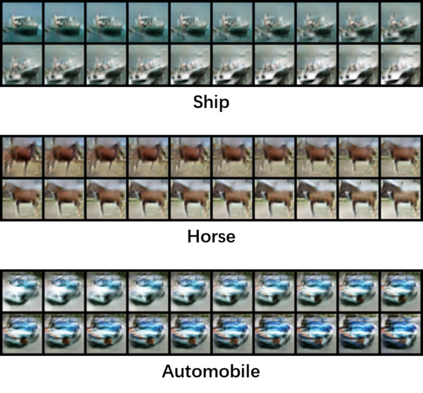
Despite its success, generative adversarial networks (GANs) still suffer from mode collapse, namely the generator can only map latent variables to a partial set of modes of the target distribution. In this paper, we analyze and try to regularize this issue with an independent and identically distributed (IID) sampling perspective and emphasize that holding the IID property for generation in target space (i.e. real data) can naturally avoid mode collapse. This is based on the basic IID assumption for real data in machine learning. However, though the source samples $\mathbf{z}$ obey IID, the target generation $G(\mathbf{z})$ may not necessarily be IID. Based on this observation, we provide a new loss to encourage the closeness between the inverse source from generation, and a standard Gaussian distribution in the latent space, as a way of regularizing the generation to be IID. The logic is that the inverse samples back from target data should also be IID for source distribution. Experiments on both synthetic and real-world data show the superiority and robustness of our model.
翻译:尽管取得了成功,但基因对抗网络(GANs)仍然受到模式崩溃的影响,即生成器只能绘制目标分布模式部分模式的潜在变量。在本文中,我们用独立和同样分布的(IID)抽样角度分析和尝试将这一问题正规化,并强调在目标空间(即真实数据)保留生成的 IID 属性自然可以避免模式崩溃。这是基于机器学习中真实数据的基本 IID假设。然而,尽管源样本$\mathbf{z}遵守IID,但目标生成量$G(mathbf{z})不一定是IID。基于这一观察,我们提供了新的损失,鼓励代的反源与潜在空间的标准高斯分布之间的近距离,作为将生成量正规化为 IID的一种方式。逻辑是,目标数据中的反面样本也应该是用于源分配。对合成和真实世界数据的实验显示了我们模型的优越性和坚固性。