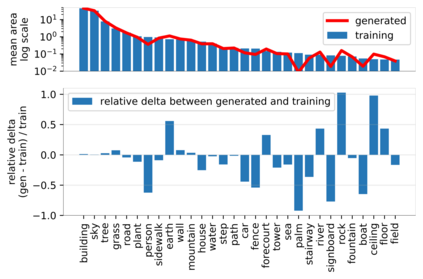
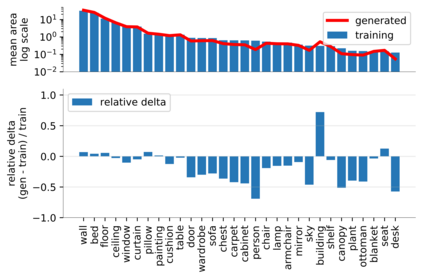
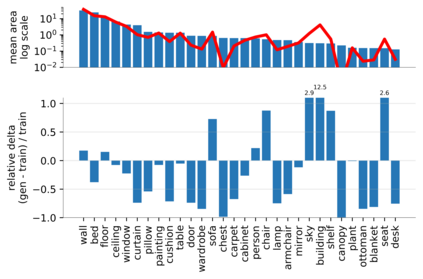
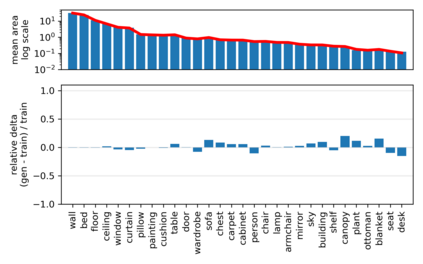
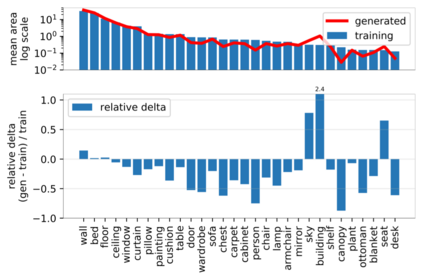
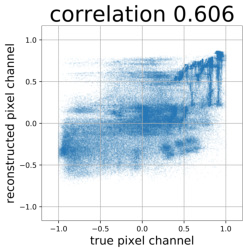
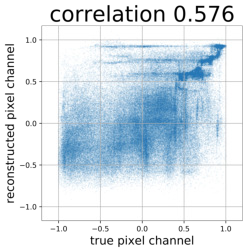
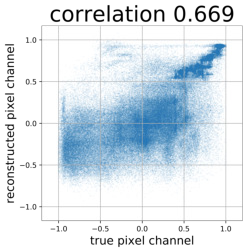
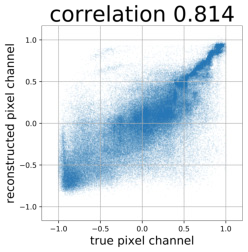
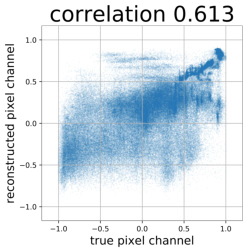
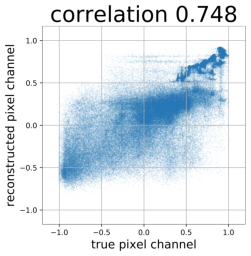
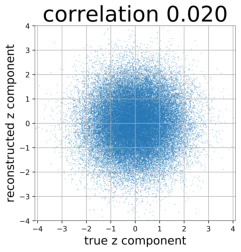
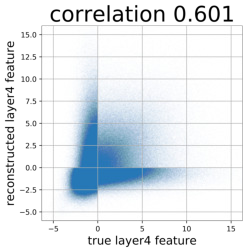
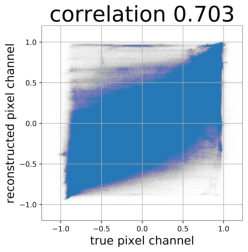
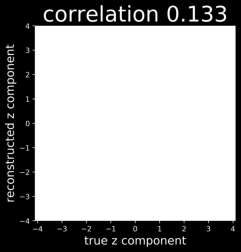
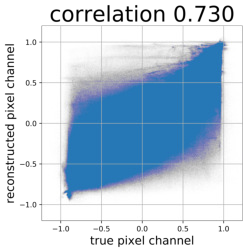
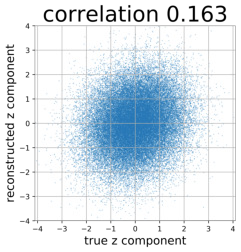
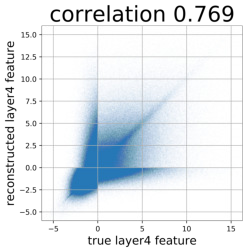
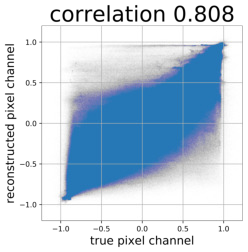
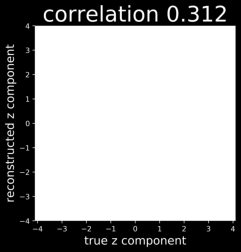
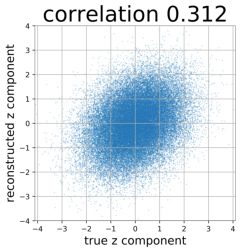
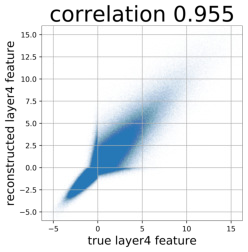
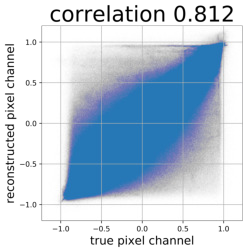
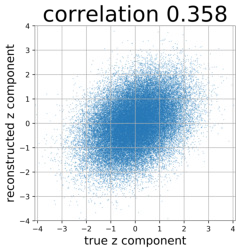
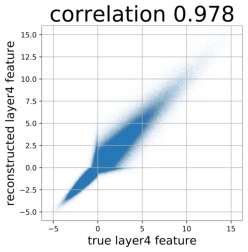
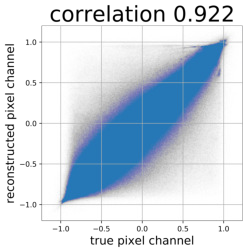
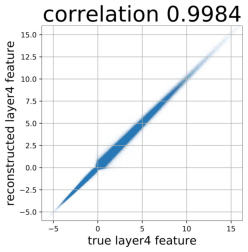
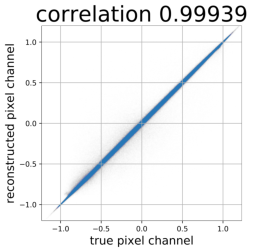
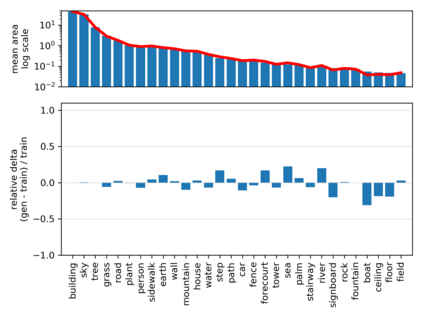
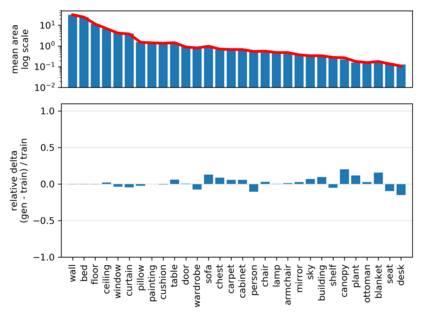
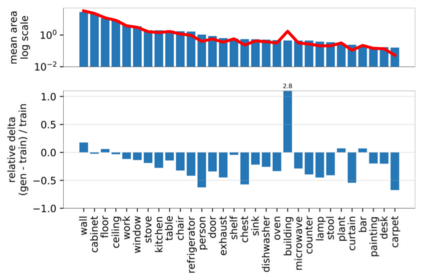
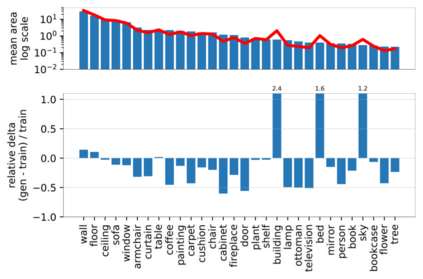
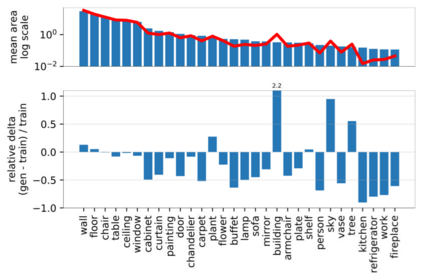
Despite the success of Generative Adversarial Networks (GANs), mode collapse remains a serious issue during GAN training. To date, little work has focused on understanding and quantifying which modes have been dropped by a model. In this work, we visualize mode collapse at both the distribution level and the instance level. First, we deploy a semantic segmentation network to compare the distribution of segmented objects in the generated images with the target distribution in the training set. Differences in statistics reveal object classes that are omitted by a GAN. Second, given the identified omitted object classes, we visualize the GAN's omissions directly. In particular, we compare specific differences between individual photos and their approximate inversions by a GAN. To this end, we relax the problem of inversion and solve the tractable problem of inverting a GAN layer instead of the entire generator. Finally, we use this framework to analyze several recent GANs trained on multiple datasets and identify their typical failure cases.
翻译:尽管Generation Adversarial Networks(GANs)取得了成功,但模式崩溃在GAN培训期间仍然是一个严重的问题。迄今为止,几乎没有什么工作侧重于理解和量化模式被模型丢弃的模式。在这项工作中,我们将模式崩溃在分布层和实例层中想象出来。首先,我们部署一个语义分割网,将生成图像中分离对象的分布与培训集的目标分布进行比较。统计数据的差异揭示了被GAN省略的物体类别。第二,根据已查明的遗漏对象类别,我们直接将GAN的遗漏进行视觉化。特别是,我们比较了个人照片与GAN的近似反相之间的差异。为此,我们放松了反转的问题,并解决了将GAN层与整个生成器反转的可移动问题。最后,我们利用这个框架来分析最近几个经过多套数据集培训的GAN,并查明其典型的失败案例。