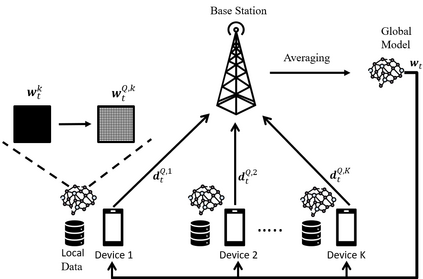
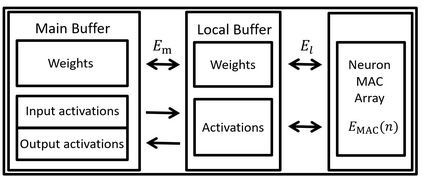
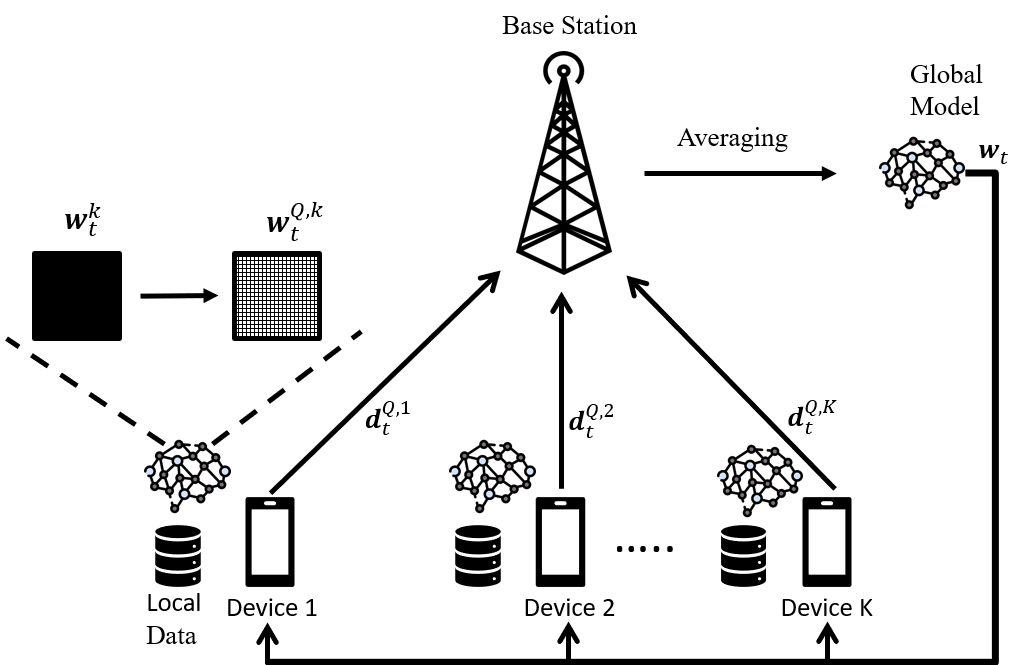
Deploying federated learning (FL) over wireless networks with resource-constrained devices requires balancing between accuracy, energy efficiency, and precision. Prior art on FL often requires devices to train deep neural networks (DNNs) using a 32-bit precision level for data representation to improve accuracy. However, such algorithms are impractical for resource-constrained devices since DNNs could require execution of millions of operations. Thus, training DNNs with a high precision level incurs a high energy cost for FL. In this paper, a quantized FL framework, that represents data with a finite level of precision in both local training and uplink transmission, is proposed. Here, the finite level of precision is captured through the use of quantized neural networks (QNNs) that quantize weights and activations in fixed-precision format. In the considered FL model, each device trains its QNN and transmits a quantized training result to the base station. Energy models for the local training and the transmission with the quantization are rigorously derived. An energy minimization problem is formulated with respect to the level of precision while ensuring convergence. To solve the problem, we first analytically derive the FL convergence rate and use a line search method. Simulation results show that our FL framework can reduce energy consumption by up to 53% compared to a standard FL model. The results also shed light on the tradeoff between precision, energy, and accuracy in FL over wireless networks.
翻译:在有资源限制的装置的无线网络上部署联合学习(FL)需要平衡精度、能源效率和精确度。关于FL的前艺术通常要求用32位精确度来训练深神经网络(DNNS),使用32位精确度来进行数据表述,以提高准确性。然而,这种算法对于资源限制的装置来说是不切实际的,因为DNNP可能需要执行数百万次操作。因此,高精确度培训DNNP为FL带来很高的能源成本。在本文中,建议了一个量化的FL框架,它代表了当地培训和上链路传输方面有限精确度的数据。在这里,通过使用量化的神经网络(QNNN)来训练深神经网络(DNNS)来提高精确度。但是,这种算法对于资源限制的装置来说是不切分量,因为DNNP可能要求执行数百万次操作。因此,高精确度培训DNNNP将一个量化的培训结果传送给基础站。在本文中,提出了一个量化的F培训的能源模型。首先在精确度和上制定了能源最小化问题,在F精确度网络上与精确度的精确度上,同时确保F的精确度的精确度的精确度的精确度,同时进行对比。SimL结果。通过SimL的搜索法的检索的计算,可以解决F的精确度,然后使F的能源标准的结果。通过F的精确度能的精确度的计算。