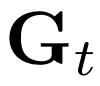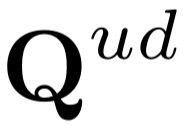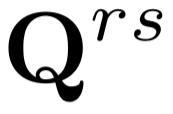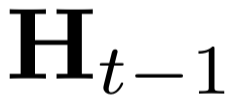Crowd counting has drawn more attention because of its wide application in smart cities. Recent works achieved promising performance but relied on the supervised paradigm with expensive crowd annotations. To alleviate annotation cost, in this work we proposed a semi-supervised learning framework S4-Crowd, which can leverage both unlabeled/labeled data for robust crowd modelling. In the unsupervised pathway, two self-supervised losses were proposed to simulate the crowd variations such as scale, illumination, etc., based on which and the supervised information pseudo labels were generated and gradually refined. We also proposed a crowd-driven recurrent unit Gated-Crowd-Recurrent-Unit (GCRU), which can preserve discriminant crowd information by extracting second-order statistics, yielding pseudo labels with improved quality. A joint loss including both unsupervised/supervised information was proposed, and a dynamic weighting strategy was employed to balance the importance of the unsupervised loss and supervised loss at different training stages. We conducted extensive experiments on four popular crowd counting datasets in semi-supervised settings. Experimental results suggested the effectiveness of each proposed component in our S4-Crowd framework. Our method also outperformed other state-of-the-art semi-supervised learning approaches on these crowd datasets.
翻译:最近的工作取得了有希望的业绩,但依赖监督的范式,并附有昂贵的人群批注。为了减轻批注成本,我们在这项工作中提出了一个半监督的学习框架S4-Crowd(S4-Crowd),它可以将未贴标签/贴标签的数据用于稳健的人群建模。在无人监督的路径中,提出了两个自我监督的损失,以模拟人群变异,如规模、照明等,在此基础上产生并逐步改进了受监督的信息假标签。我们还提议了一个由人群驱动的经常单位Growd-Rive-Unit(GCRU),通过提取二阶统计数据,产生质量更高的伪标签,可以保存不愉快的人群信息。提出了包括未经监督/看管信息在内的联合损失,并采用了动态加权战略,以平衡非监督的损失和在不同培训阶段受监督的损失的重要性。我们还对在半监督的环境中的四个人群群点计算数据集进行了广泛的实验。实验结果也建议了我们每个拟议采用的S-C 模型模型方法的每个组合方法的有效性。