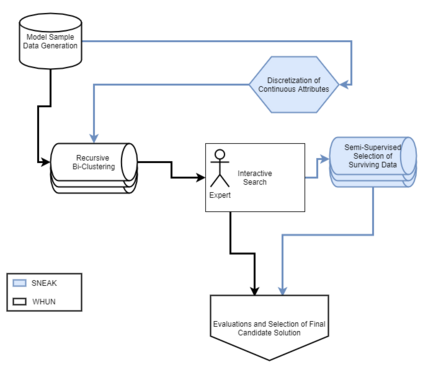
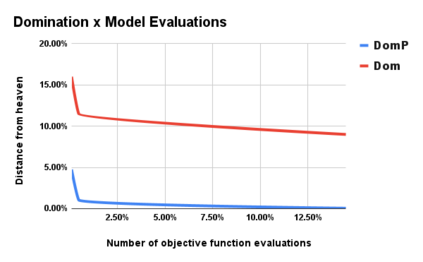
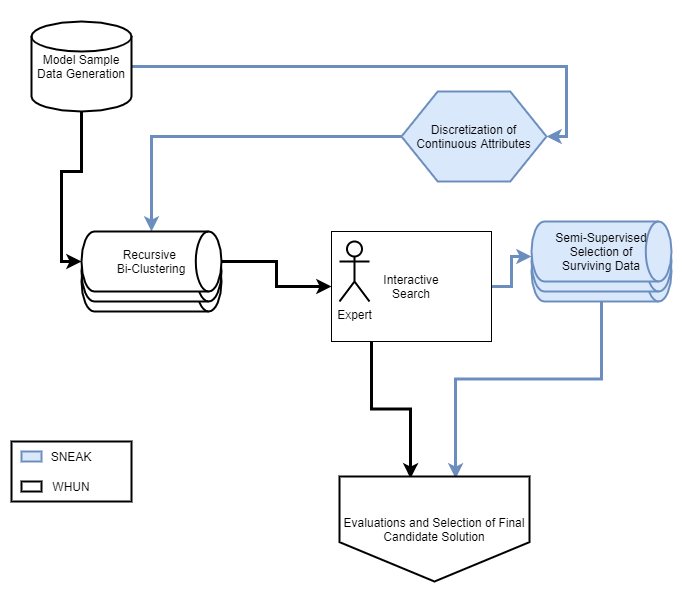
When reasoning over complex models, AI tools can generate too many solutions for humans to read and understand. In this case, \textit{interactive search-based software engineering} techniques might use human preferences to select relevant solutions (and discard the rest). Often, iSBSE methods rely on evolutionary methods that need to score thousands of mutants. Generating those scores can be overwhelming for humans or impractically slow (e.g. if some automated process required extensive CPU to computer those scores). To address that problem, this paper introduces SNEAK, a semi-supervised learner (SSL) that uses the structure of the data to label a very small number of points, then propagates those labels over its neighbors. Whereas standard SSL addresses single goal problems (classification, regression), \sffamily{SNEAK} is unique in that it can handle multi-goal problems. As shown by the experiments of this paper, SNEAK asks for very few labels (30, or even less) even for models with 1000 variables and state spaces of $2^{1000}$ possibilities. Also, the optimization solutions found in this way were within the best 1\% of the entire space of solutions. Further, due to the logarithmic nature of its search, in theory, SNEAK should scale well to very large problems. Accordingly, we recommend SNEAKing since, at the very least, it is a baseline architecture against which other iSBSE work can be compared. To enable that comparison, all of ours scripts are available at https://github.com/zxcv123456qwe/sneak.
翻译:当对复杂模型进行推理时, AI 工具可以产生太多的解决方案, 供人类阅读和理解。 在此情况下, 使用 extextit{ 互动搜索基础软件工程} 技术可能会使用人类偏好来选择相关解决方案( 并丢弃其余部分 ) 。 通常, ISBSE 方法依赖进化方法, 需要得上千变种。 生成这些得分对于人类来说可能是压倒性的, 或者不切实际地缓慢( 例如, 如果某些自动化程序需要大量的CPU来计算这些得分 ) 。 为了解决这个问题, 本文引入了 SNEAIC, 即半受监督的学习者( SSL ), 使用数据结构来标出非常小的点, 然后在邻居之间传播这些标签。 而标准的SSLSL 方法则取决于单个目标问题( 分类、 回归 ),\ sSBSW {SF} 方法的独特之处在于它能够处理多的目标问题 12 的标签( 30 或更少 ) ) 。, 甚至更少地), 即使是有1000 变量的模型 和 $10000 的状态空间 的可能性。 。此外的模型中找到最优化的 iSISSISB 。