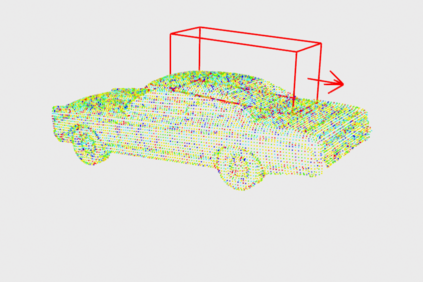
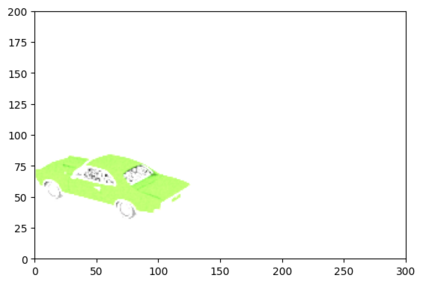
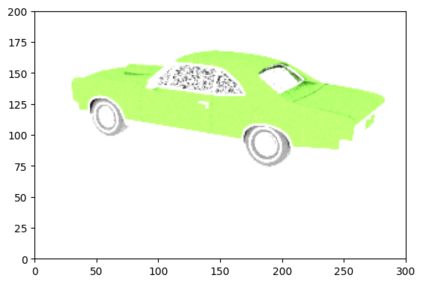
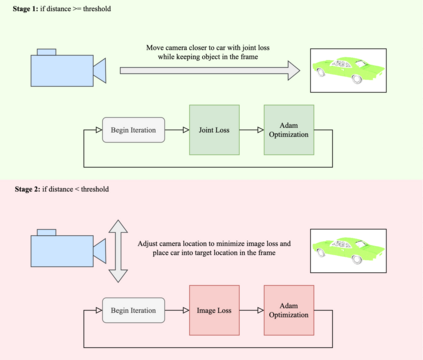
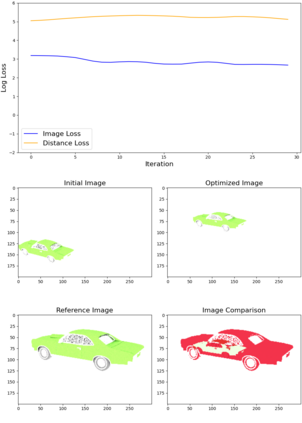
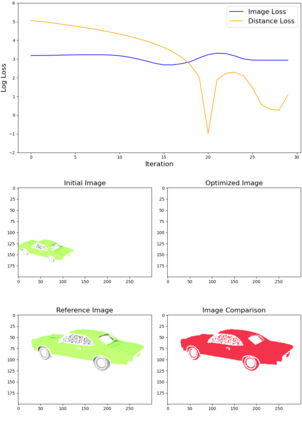
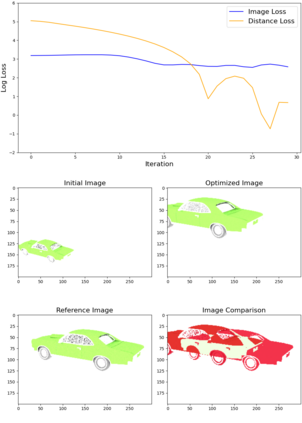
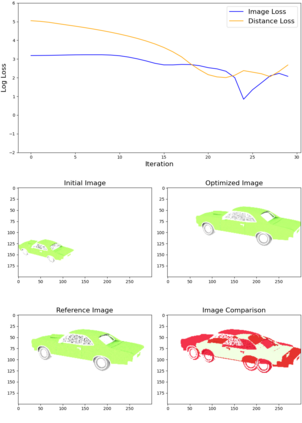
This article describes a multi-modal method using simulated Lidar data via ray tracing and image pixel loss with differentiable rendering to optimize an object's position with respect to an observer or some referential objects in a computer graphics scene. Object position optimization is completed using gradient descent with the loss function being influenced by both modalities. Typical object placement optimization is done using image pixel loss with differentiable rendering only, this work shows the use of a second modality (Lidar) leads to faster convergence. This method of fusing sensor input presents a potential usefulness for autonomous vehicles, as these methods can be used to establish the locations of multiple actors in a scene. This article also presents a method for the simulation of multiple types of data to be used in the training of autonomous vehicles.
翻译:暂无翻译