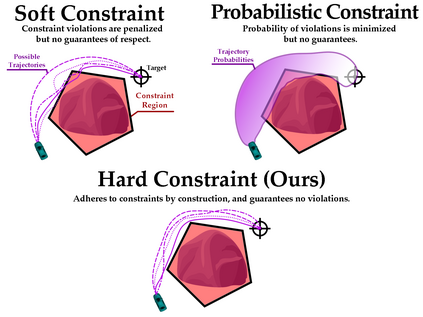
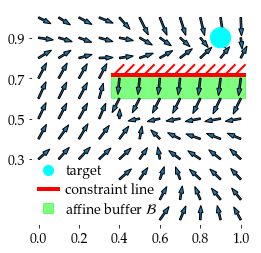
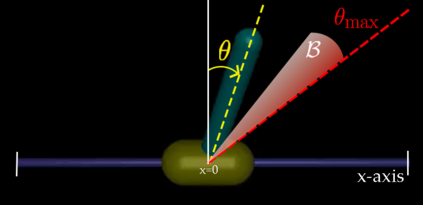
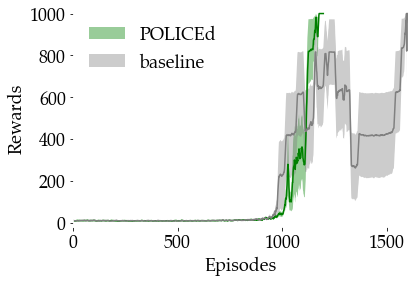
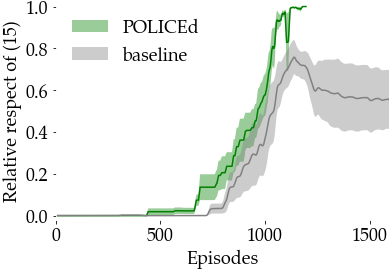
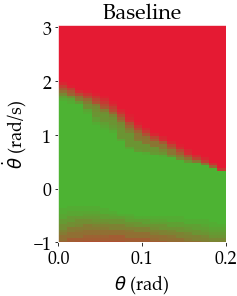
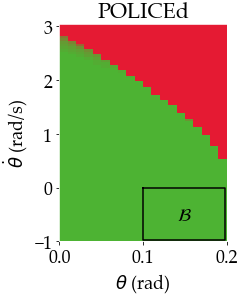
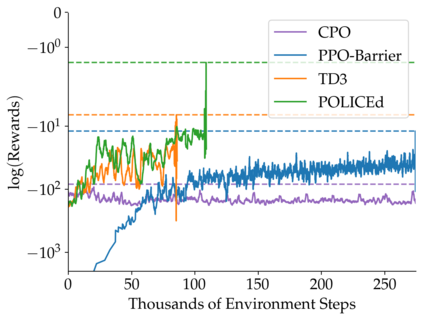
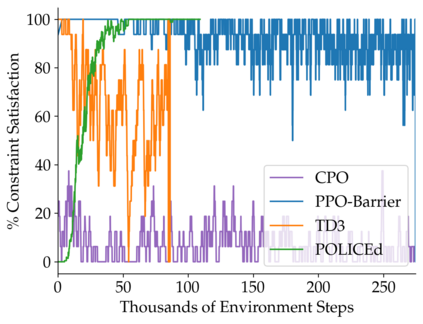
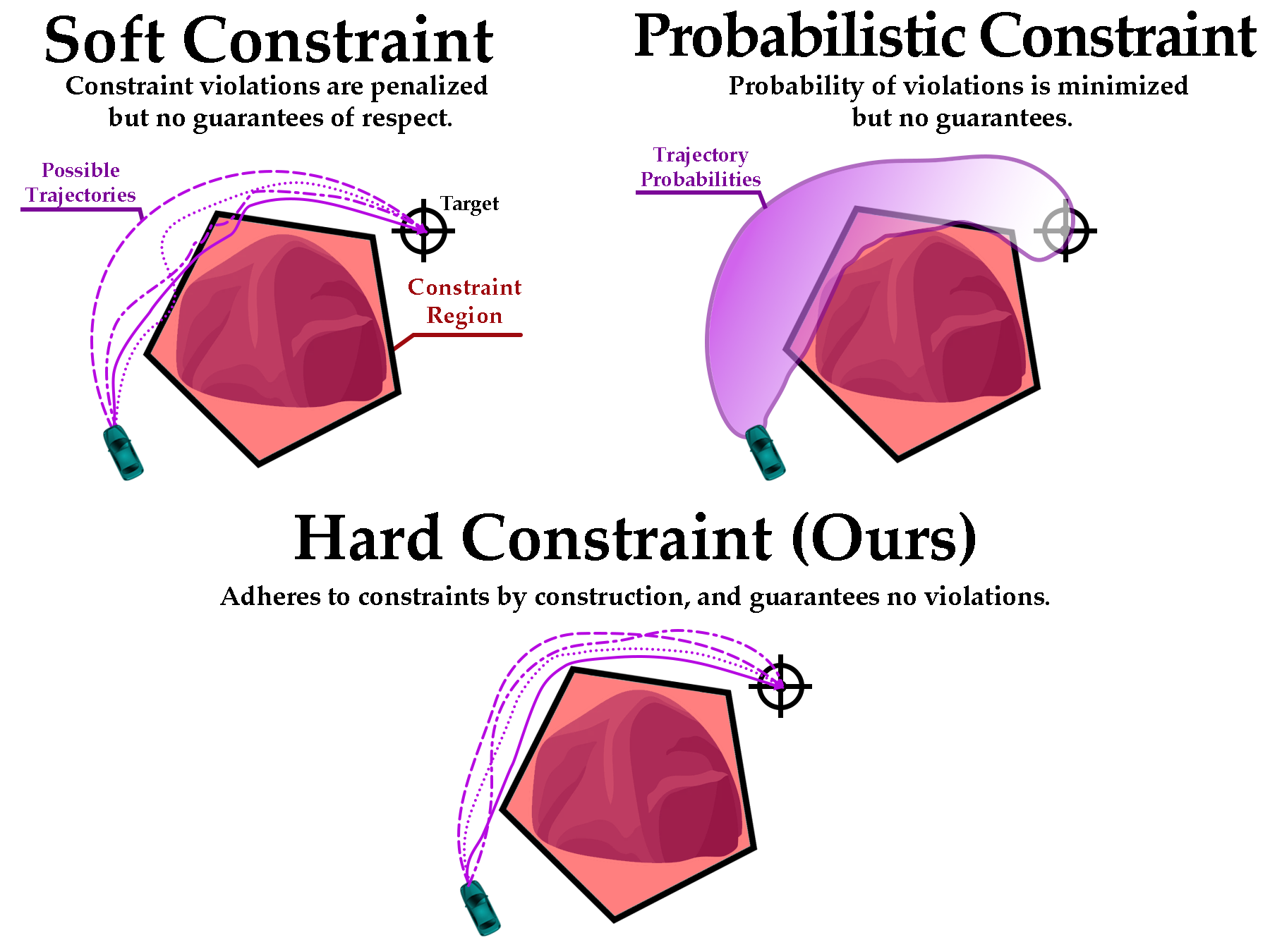
In this paper, we seek to learn a robot policy guaranteed to satisfy state constraints. To encourage constraint satisfaction, existing RL algorithms typically rely on Constrained Markov Decision Processes and discourage constraint violations through reward shaping. However, such soft constraints cannot offer verifiable safety guarantees. To address this gap, we propose POLICEd RL, a novel RL algorithm explicitly designed to enforce affine hard constraints in closed-loop with a black-box environment. Our key insight is to force the learned policy to be affine around the unsafe set and use this affine region as a repulsive buffer to prevent trajectories from violating the constraint. We prove that such policies exist and guarantee constraint satisfaction. Our proposed framework is applicable to both systems with continuous and discrete state and action spaces and is agnostic to the choice of the RL training algorithm. Our results demonstrate the capacity of POLICEd RL to enforce hard constraints in robotic tasks while significantly outperforming existing methods.
翻译:暂无翻译