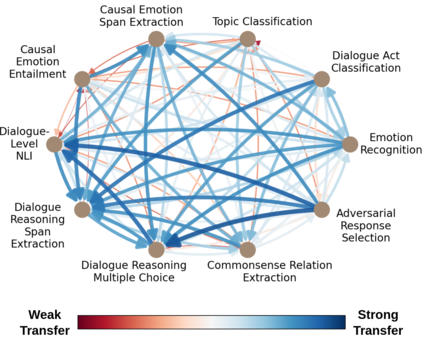
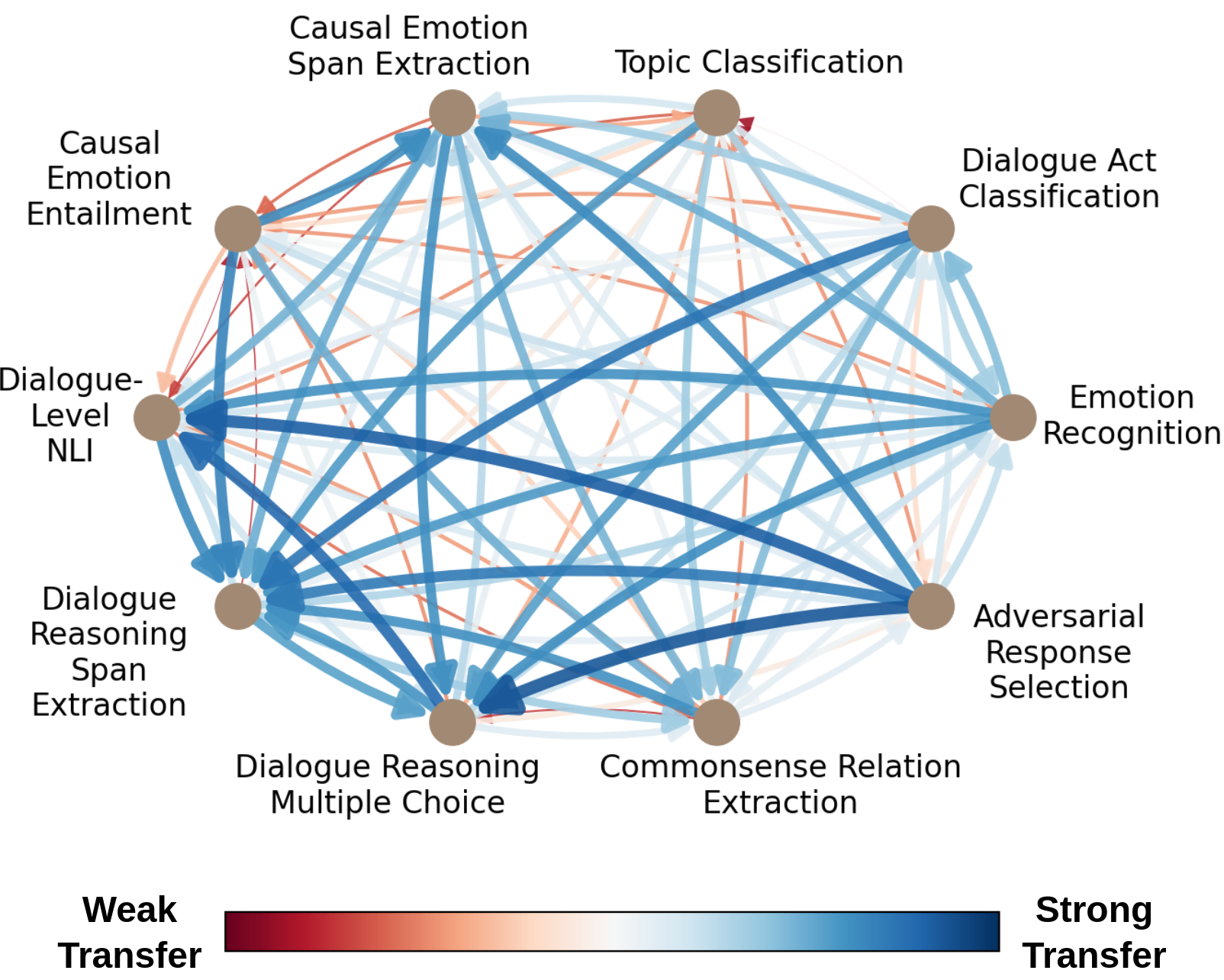
Task transfer, transferring knowledge contained in related tasks, holds the promise of reducing the quantity of labeled data required to fine-tune language models. Dialogue understanding encompasses many diverse tasks, yet task transfer has not been thoroughly studied in conversational AI. This work explores conversational task transfer by introducing FETA: a benchmark for few-sample task transfer in open-domain dialogue. FETA contains two underlying sets of conversations upon which there are 10 and 7 tasks annotated, enabling the study of intra-dataset task transfer; task transfer without domain adaptation. We utilize three popular language models and three learning algorithms to analyze the transferability between 132 source-target task pairs and create a baseline for future work. We run experiments in the single- and multi-source settings and report valuable findings, e.g., most performance trends are model-specific, and span extraction and multiple-choice tasks benefit the most from task transfer. In addition to task transfer, FETA can be a valuable resource for future research into the efficiency and generalizability of pre-training datasets and model architectures, as well as for learning settings such as continual and multitask learning.
翻译:任务转移、相关任务所包含的知识转让,有可能减少调整语言模式所需的标签数据数量,对话理解包含许多不同任务,但任务转移尚未在对话性AI中进行彻底研究。这项工作通过引入FETA探索对话任务转移:在开放式对话中进行几类抽样任务转移的基准。FETA包含两组基本对话,其中附有10项和7项附加说明的任务,使得能够研究数据集内任务转移;任务转移,而没有领域调整。我们利用三种流行语言模式和三种学习算法来分析132对源目标任务组合之间的可转让性,并为未来工作制定基准。我们在单一和多源环境进行实验,并报告有价值的结果,例如,大多数业绩趋势是针对具体模式的,而抽取和多重选择任务最能从任务转移中受益。除了任务转移之外,FETA还可以成为今后研究培训前数据集和模型结构的效率和可概括性的宝贵资源,以及学习环境,如持续和多任务学习。