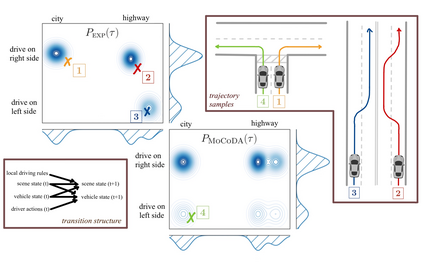
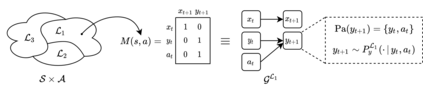
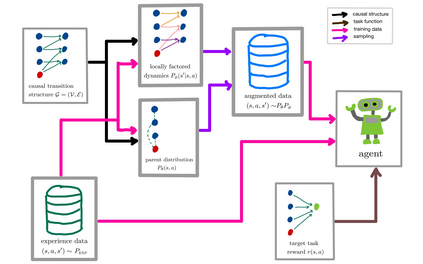
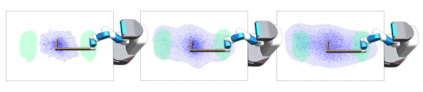
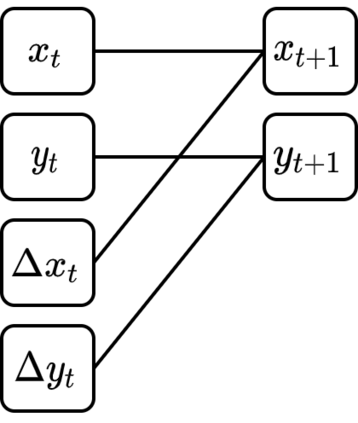
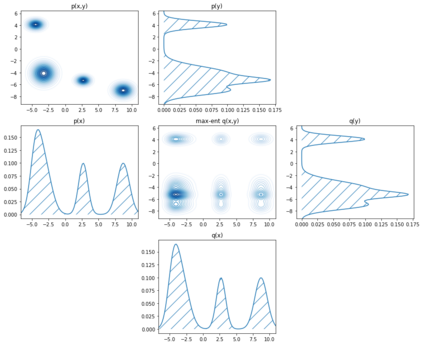
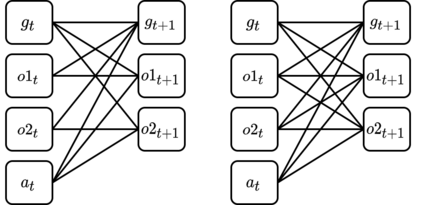
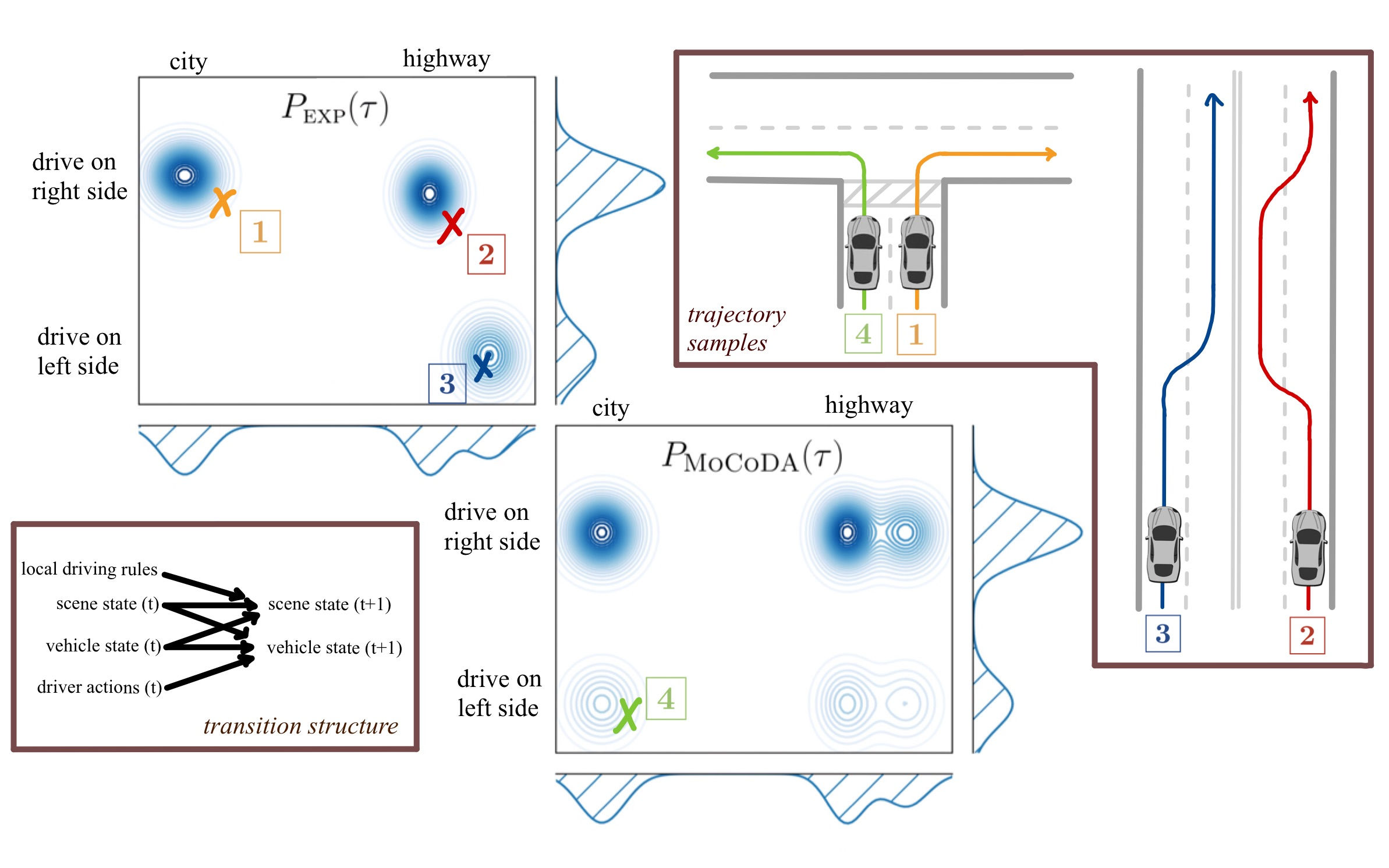
The number of states in a dynamic process is exponential in the number of objects, making reinforcement learning (RL) difficult in complex, multi-object domains. For agents to scale to the real world, they will need to react to and reason about unseen combinations of objects. We argue that the ability to recognize and use local factorization in transition dynamics is a key element in unlocking the power of multi-object reasoning. To this end, we show that (1) known local structure in the environment transitions is sufficient for an exponential reduction in the sample complexity of training a dynamics model, and (2) a locally factored dynamics model provably generalizes out-of-distribution to unseen states and actions. Knowing the local structure also allows us to predict which unseen states and actions this dynamics model will generalize to. We propose to leverage these observations in a novel Model-based Counterfactual Data Augmentation (MoCoDA) framework. MoCoDA applies a learned locally factored dynamics model to an augmented distribution of states and actions to generate counterfactual transitions for RL. MoCoDA works with a broader set of local structures than prior work and allows for direct control over the augmented training distribution. We show that MoCoDA enables RL agents to learn policies that generalize to unseen states and actions. We use MoCoDA to train an offline RL agent to solve an out-of-distribution robotics manipulation task on which standard offline RL algorithms fail.
翻译:动态进程中的国家数量在物体数量上呈指数化,使强化学习(RL)在复杂多球域中难以在复杂多球域中进行,使强化学习(RL)难于在复杂多球域中进行。对于向真实世界扩展的代理商来说,它们将需要对不可见的物体组合作出反应和理性。我们认为,在过渡动态中承认和使用当地因素化的能力是释放多球推理能力的一个关键要素。为此,我们显示:(1) 环境转型中已知的当地结构足以使培训动态模型的抽样复杂性急剧减少,(2) 当地因素化动态模型可以被可调和地概括到向隐形国家和行动传播。了解当地结构还使我们能够预测哪些不可见的物体和这种动态模型将概括起来。我们提议在基于模型的反事实数据放大框架中利用这些观测结果。 MOCODA应用一个学习当地因素的动态模型模型来扩大各州的分布和行动,以产生反事实性转变,为RL。 MODA与比先前的工作和行动的分布允许直接控制RDA的RA工具进行升级。