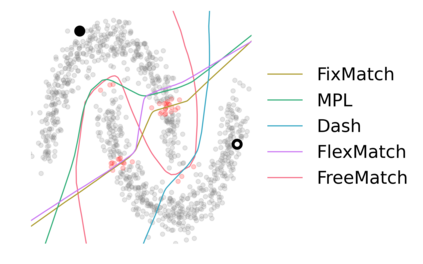
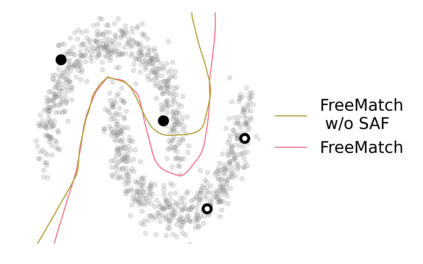
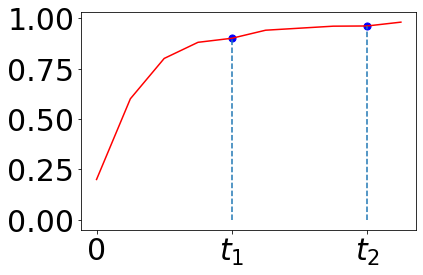
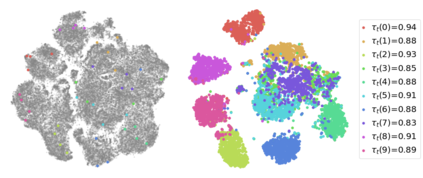
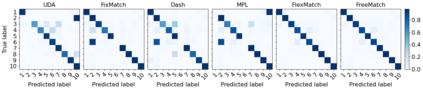
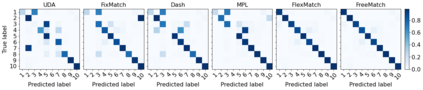
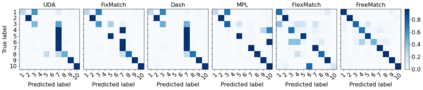
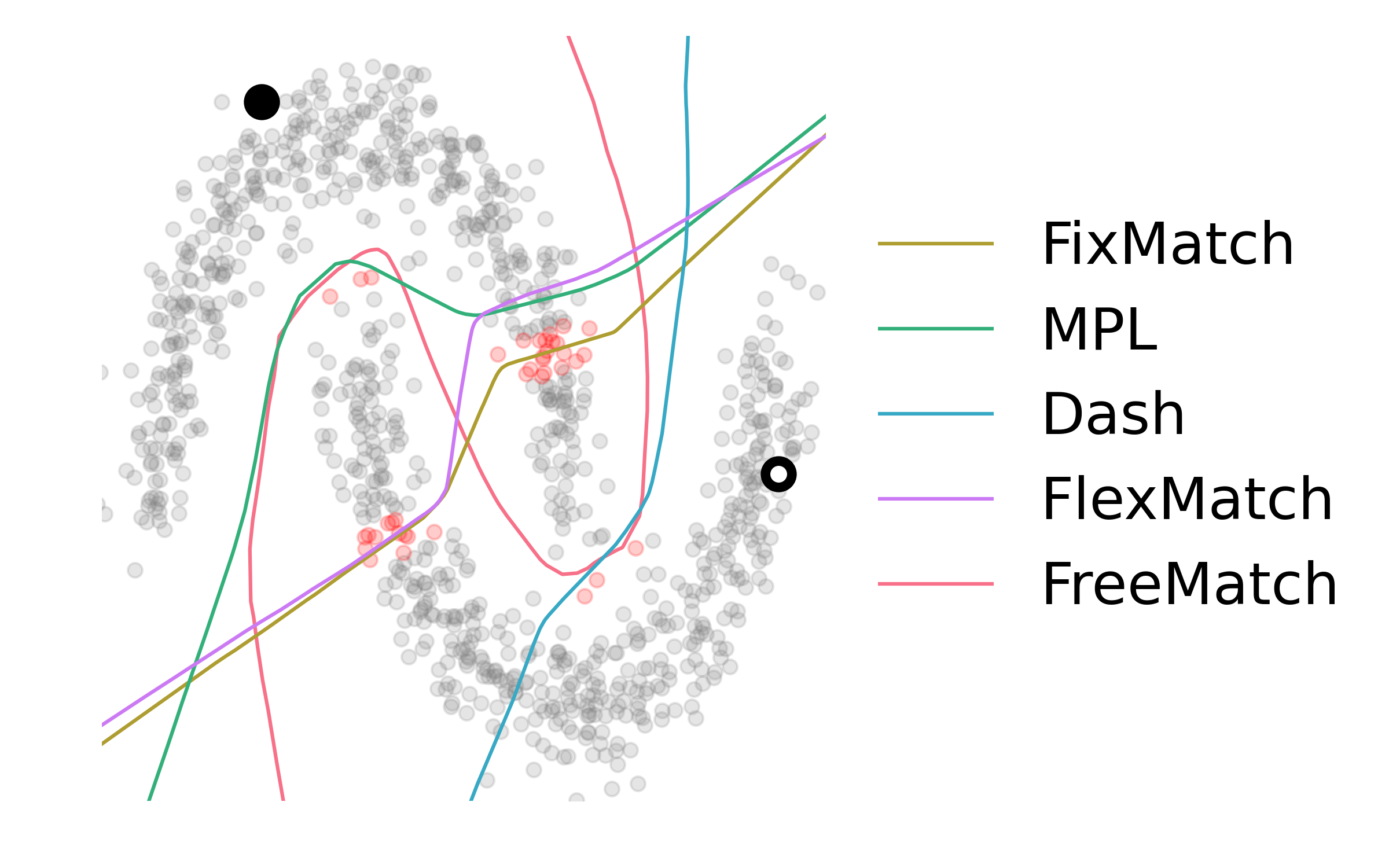
Pseudo labeling and consistency regularization approaches based on confidence thresholding have made great progress in semi-supervised learning (SSL). However, we argue that existing methods might fail to adopt suitable thresholds since they either use a pre-defined / fixed threshold or an ad-hoc threshold adjusting scheme, resulting in inferior performance and slow convergence. We first analyze a motivating example to achieve some intuitions on the relationship between the desirable threshold and model's learning status. Based on the analysis, we hence propose FreeMatch to define and adjust the confidence threshold in a self-adaptive manner according to the model's learning status. We further introduce a self-adaptive class fairness regularization penalty that encourages the model to produce diverse predictions during the early stages of training. Extensive experimental results indicate the superiority of FreeMatch especially when the labeled data are extremely rare. FreeMatch achieves 5.78%, 13.59%, and 1.28% error rate reduction over the latest state-of-the-art method FlexMatch on CIFAR-10 with 1 label per class, STL-10 with 4 labels per class, and ImageNet with 100 labels per class, respectively.
翻译:以信任阈值为基础的普塞多标签和一致性规范化方法在半监督学习(SSL)方面取得了很大进展。然而,我们认为,现有方法可能无法采用合适的阈值,因为它们使用预先确定的/固定阈值或临时的阈值调整计划,导致业绩低下和趋同速度缓慢。我们首先分析一个激励性范例,以获得关于理想阈值与模型学习状态之间关系的一些直觉。根据分析,我们因此建议自由匹配公司根据模型的学习状况,以自我适应的方式界定和调整信任阈值。我们进一步引入了自适应性阶级公平化处罚,鼓励模型在培训的早期阶段作出多种预测。广泛的实验结果表明自由匹配的优越性,特别是当标签数据极为罕见时。自由Match公司实现了5.78%、13.59%和1.28%的误差率,超过最新的CIFAR-10号工艺级FlexMatch公司的最新FlexMatch,每类有1个标签,STL-10,每类有4个标签,每类有100个图像网。