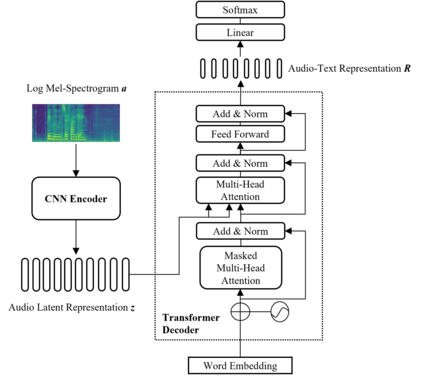
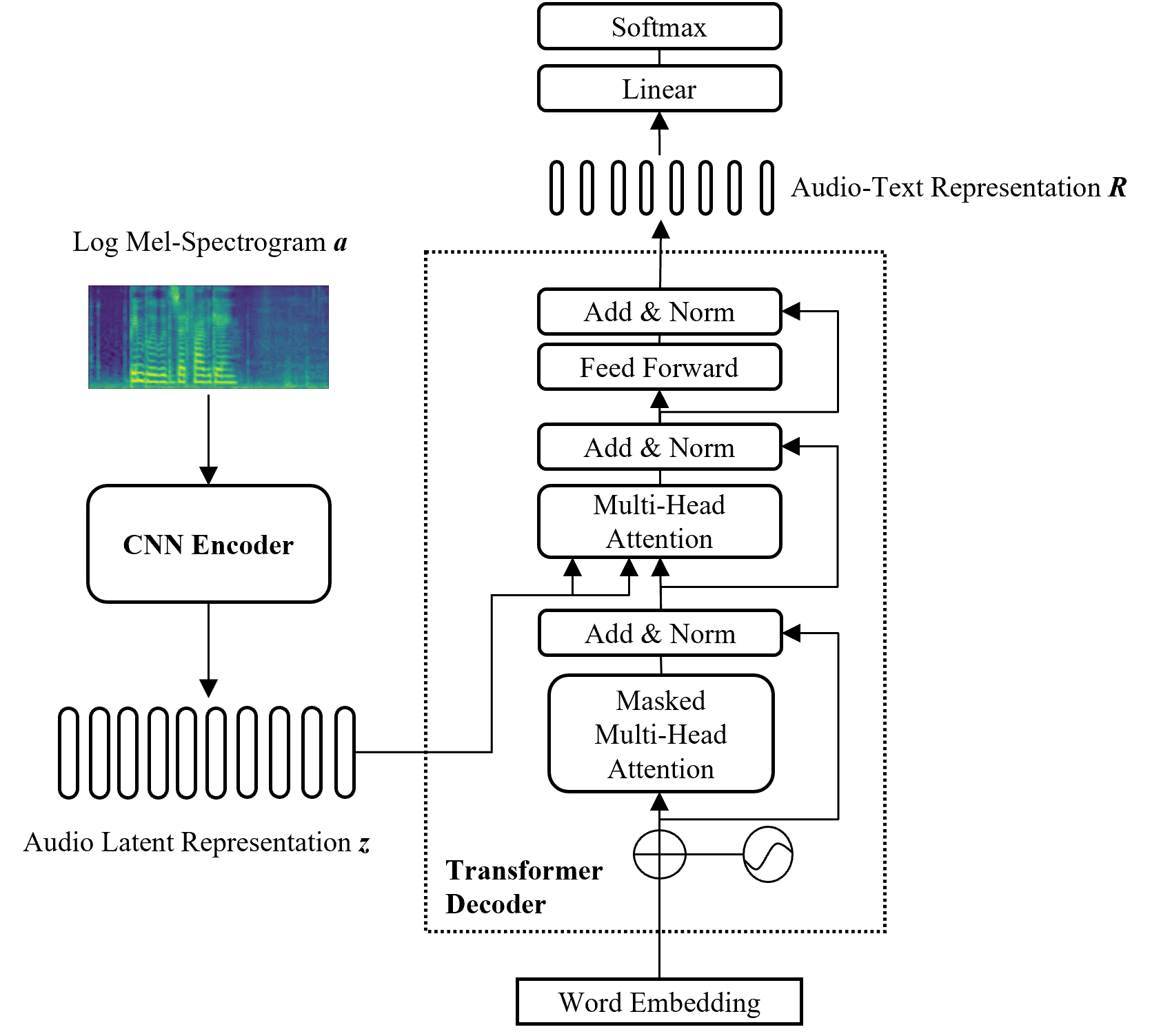
Automated Audio captioning (AAC) is a cross-modal translation task that aims to use natural language to describe the content of an audio clip. As shown in the submissions received for Task 6 of the DCASE 2021 Challenges, this problem has received increasing interest in the community. The existing AAC systems are usually based on an encoder-decoder architecture, where the audio signal is encoded into a latent representation, and aligned with its corresponding text descriptions, then a decoder is used to generate the captions. However, training of an AAC system often encounters the problem of data scarcity, which may lead to inaccurate representation and audio-text alignment. To address this problem, we propose a novel encoder-decoder framework called Contrastive Loss for Audio Captioning (CL4AC). In CL4AC, the self-supervision signals derived from the original audio-text paired data are used to exploit the correspondences between audio and texts by contrasting samples, which can improve the quality of latent representation and the alignment between audio and texts, while trained with limited data. Experiments are performed on the Clotho dataset to show the effectiveness of our proposed approach.
翻译:自动音频字幕(AAC)是一项跨模式翻译任务,目的是使用自然语言描述音频剪辑的内容。正如为DCASE 2021挑战第6号任务收到的提交材料所示,这一问题在社区中受到越来越多的关注。现有的AAC系统通常基于编码器脱代码器结构,其中音频信号编码成潜代号,并与相应的文本说明相一致,然后使用解码器生成字幕。然而,AAC系统的培训常常遇到数据稀缺问题,这可能导致陈述不准确和音频文本协调。为了解决这一问题,我们提议了一个名为“声音捕获的对比丢失”的新的编码解码器框架。在CL4AC中,从原始的音频文本配对数据中产生的自我监督信号被用于通过对比样本来利用音频和文本之间的对应,这可以提高潜在表述的质量,使音频和文本之间的一致性得到改进,同时用有限的数据加以培训。在Clotho数据上进行了实验,以显示我们拟议的数据的有效性。