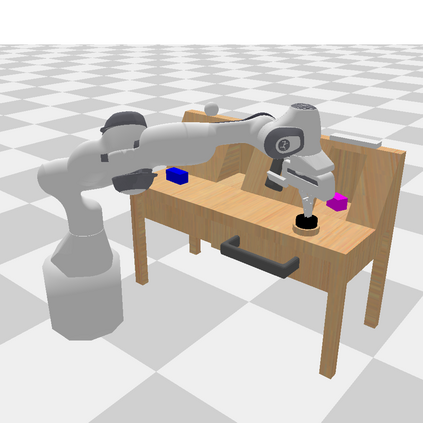
General-purpose robots coexisting with humans in their environment must learn to relate human language to their perceptions and actions to be useful in a range of daily tasks. Moreover, they need to acquire a diverse repertoire of general-purpose skills that allow composing long-horizon tasks by following unconstrained language instructions. In this paper, we present CALVIN (Composing Actions from Language and Vision), an open-source simulated benchmark to learn long-horizon language-conditioned tasks. Our aim is to make it possible to develop agents that can solve many robotic manipulation tasks over a long horizon, from onboard sensors, and specified only via human language. CALVIN tasks are more complex in terms of sequence length, action space, and language than existing vision-and-language task datasets and supports flexible specification of sensor suites. We evaluate the agents in zero-shot to novel language instructions and to novel environments and objects. We show that a baseline model based on multi-context imitation learning performs poorly on CALVIN, suggesting that there is significant room for developing innovative agents that learn to relate human language to their world models with this benchmark.
翻译:与环境中的人类共存的通用机器人必须学会将人文与其感知和行动联系起来,以便在一系列日常任务中发挥作用;此外,他们需要获得多种通用技能,以便通过不受限制的语言指示来形成长视线任务;在本文件中,我们介绍CALVIN(语言和愿景行动),这是一个用于学习长视语言任务的一个开放源模拟基准;我们的目标是,使开发能够从机载传感器和仅通过人文指定的远程解决许多机器人操纵任务的代理商成为可能;CALVIN的任务在序列长度、行动空间和语言方面比现有的视觉和语言任务数据集更为复杂,并支持感官套装具的灵活规格;我们对新语言指示和新环境及物体的代理商进行零发评估;我们显示,基于多相像学习的基线模型在CLVIN上表现不佳,这表明开发创新代理人学习与这一基准世界模型相联系的重要空间。